| | |
GAUDI User Guide
| | |
GAUDI User Guide

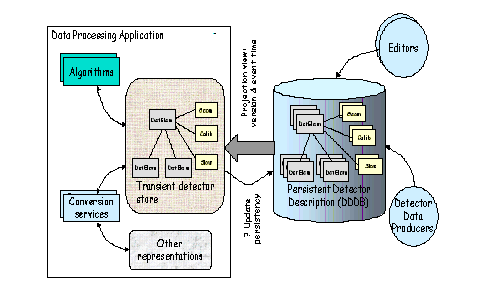
In this chapter we describe how we make available to the physics application developed using the framework the information related to the detector that resides in the detector description database (DDDB). The DDDB is the persistent storage for all the versions of the detector data needed to describe and qualify the detecting apparatus in order to interpret the event data.
The final clients of the detector description are the algorithms that need this information in order to perform their job (reconstruction, simulation, etc.). To provide this information, there needs to be a sub-detector specific part that understands the sub-detector in question and uses a set of common services. The detector description we are providing in Gaudi is nothing else than a framework for developers to provide the specific detector information to algorithms by using as much as possible common or generic services.
In the following sections we begin with an overview of the DDDB. We then discuss how to access the detector description data in the Gaudi transient detector data store. This is followed by a discussion of the logical structure of the Gaudi detector description. We then describe in detail how the detector decription can be built and made persistent using the XML markup language and finish with an introduction to an XML editing tools which allows browsing and modification of the DDDB. Please note that some new features of the detector description available in this release of Gaudi (e.g. the SolidTrap volume) have not yet been documented in this chapter
The detector description database (DDDB), see Figure 9, includes a physical and a logical description of the detector. The physical description covers dimensions, shape and material of the different types of elements from which the detector is constructed. There is also information which corresponds to each element which is actually manufactured and assembled into a detector, for example the positioning of each element. Both active and passive elements should be included. The description of active elements should allow for the specification of deficiencies (dead channels), alignment corrections, etc. and also detector response characteristics, e.g. energy normalization in calorimeters, drift velocity in gas chambers.
|
The logical description provides two main functions. The first is a simplified access to particular parts of a physical detector description. This could be a hierarchical description where a given detector setup is composed of various sub-detectors, each of which is made up of a number stations, modules or layers, etc. and there would be a simple way for a client to use this description to navigate to the information of interest. The second function of the logical description is to provide a means of detector element identification. This allows for different sets of information which are correlated to specific detector elements to be correctly associated with each other
In a detector description, the definition of the detector elements and of the data associated to their physical description may vary over time, for instance due to real or hypothetical changes to the detector. Each such change should be recorded as a different version of the detector element. Additionally, it should be possible to capture, for an entire description, a version of each of the elements and to associate a name to that set. This is similar to the way CVS allows one to tag a set of files so that one does not need to know the independent version numbers for each file in the set.
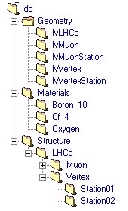
The transient representation of the detector description is implemented as a standard Gaudi data store. Refer to Chapter 6 for general information on how to access data in stores. The structure of the detector transient store is represented in Figure 10. There are various branches in the hierarchical tree structure and probably there will be more of them defined in the future.
At present there are three top level catalogs in the transient store. The main catalog, called "Structure" contains the logical structure of the detector identified by the "setup name" i.e. "LHCb" containing the description of the detector and this catalog is used for identification and navigation purposes. Other catalogs are the palette of logical volumes and solids, called "Geometry", used for the geometry description and the palette of materials, called "Materials", used to describe the material properties of the solids needed for the detector simulation, etc.
|
An algorithm that needs to access a given detector part uses the detector data service to locate the relevant
DetectorElement
. This operation of locating the required detector description object can be generally done during the initialization phase of the algorithm. Contrary to the Event Data, the Detector Data store is not cleared for each event and the references to detector elements remain valid and are updated automatically during the execution of the program. Locating the relevant detector element is done using the standard
IDataProviderSvc
interface via the detSvc() accessor as shown in Listing 18
Similarly the user can retrieve an array of such references. The following code fragment can be used to prepare an array with pointers to all of the Muon stations. Here we use an STL vector of pointers to DeMuonStation objects to store the retrieved Muon stations.
The
DetectorElement
class implements the
IDetectorElement
interface. Currently, only the
geometry()
accessor method is implemented. The rest of the interface will be implemented in the next releases of the detector description package. In addition,
DetectorElement
implements the IValidity interface. This interface is used to check if the detector element is synchronized with the current event. If the detector element contains information no longer valid at the time the current event was generated, its content must be updated from the persistent storage. In the current implementation it is not foreseen for end users to use this interface directly.
The accessor method
geometry()
gives access to geometry information offered by the interface of type
IGeometryInfo
. This interface allows the retrieval of a reference to a logical volume associated with the given detector element, its material property, the position in the geometrical hierarchy. In addition to that you can ask it questions like:
The construction of the geometry tree within the Gaudi framework is based on the following postulates:
The geometry tree which fulfils all these postulates represents a very effective, simple and convenient tool for description of the geometry. Such a tree is easily formalized. It has many features which are similar to the features of the geometry tree used within the Geant4 toolkit and could easily be transformed to the Geant4 geometry description.
Some consequences of these postulates are:
Sometimes one needs a more efficient way of extracting information from the geometry tree or to compute the unique location of a point in the geometry tree. For these purposes, a simplified detector description tree is introduced into the Gaudi framework3.
The next subsections give brief details of the implementations of Logical Volumes, Physics Volumes and Solids in Gaudi. More detailed documentation can be found at http://cern.ch/lhcb-comp/Components/html/GaudiReference.htm
The notion of Logical Volume is implemented in Gaudi by the class LVolume. LVolume is an identifiable object and therefore inherits from class DataObject and can be identified in the transient data store by a unique name (its "path"). It implements the ILVolume and IValidity interfaces.
The notion of Physical Volume in the Gaudi geometry is extremely primitive, it is just a Logical volume which is positioned inside its mother Logical Volume . It consists of the name of the Logical Volume to be positioned inside the mother Logical Volume , together with the transformation matrix from the local reference system of the mother Logical Volume to the local reference system of the daughter Logical Volume . This is implemented in Gaudi by the class PVolume. PVolume is not identifiable and implements the IPVolume interface.
All solids implement the ISolid interface. Currently, five types of "primitive" solids are implemented: Boxes, Trapezoids, Tube segments, Conical tube segments and Sphere segments . These were chosen from the most frequently used shapes in the GEANT3 and Geant4 toolkits - more shapes can be implemented if necessary. In addition, Boolean Solids have been defined, which allow Subtraction, Union and Intersection operations on solids, to build complex shapes.
The Gaudi detector description is based on text files whose structure is described by XML (eXtendable Markup Language), a standard language which allows the definition of custom tags, unlike the fixed set of tags of HTML used for WWW. XML files are understandable by humans as well as computers. Data in XML are self-descriptive so that by looking at the XML data one can easily guess what the data mean. Unlike the HTML tags, tags in XML do not define how to render or visualize the data. This is left to an application which understands the data and can visualize them if wanted. An advantage of XML is that there exists plenty of software which can be used for parsing and analysing, as it is an industry standard.
In the future we expect to replace the text files by an object persistency based on an object oriented database, for example ObjectivityDB, but the data will continue to be described in XML.
XML is extendible, meaning that a user can define his own markup language with his own tags. The tags define the meaning of the data they represent or contain. They act as data describers. For example, Listing 21 shows the XML file which describes an e-mail.
At first look this markup language looks like screwed-up HTML. This is because both HTML and XML have their roots in SGML, but they are used for different purposes. From the example above it's not clear how to present the data described there nor how to visualize them. What is clear however is the meaning of the data items encoded in XML. Thus one can easily recognize the data items and guess what they mean. On the other hand it is relatively easy to instruct a computer program what to do with the given data item according to the XML markup elements it is encapsulated in. Let us analyse the example shown above.
must be at the beginning of each XML document. It is the first line in the example. It says that this file is an XML file conforming to the XML standard version 1.0 and is encoded in UTF-8 encoding. The encoding is very important because XML has been designed to describe data using the Unicode standard for text encoding. This means that all XML documents are treated as 16 bit Unicode characters instead of usual ASCII. So, even if you write your XML files using 7 or 8 bit ASCII, all the XML applications will work with it as with 16 bit Unicode XML data. The encoding information is important, for example when an XML document is transferred over the Internet to some other country where a different encoding is used. If the receiving application can guess the XML encoding from the received file, it can apply transcoding methods to convert the file into proper local encoding, thus preserving readability of the data.
look like comments in SGML or HTML. They start with <!-- and end with -->. Comments in XML cannot be nested.
are the markup components describing data in XML. In the example we had the following XML elements: Email, TimeStamp, Sender, Recipient, Subject, Body, Signature. The very basic and mandatory rule of XML is that all XML element tags must nest properly and there must be only one root XML element at the top level of each XML document, which contains all the others. Proper nesting means that each XML element has its opening and closing tag and the closing tag must appear before the parent element's closing tag, as shown in Listing 22. Following these rules one can always produce well-formed XML documents.
XML elements can have attributes and a content. Attributes usually describe the properties of the given element. The value of the attribute follows the assignment operator and is enclosed inside double or single quotes.In the content can appear text data or other properly nested elements. The text data and nested elements can be mixed inside the content.
A well formed XML document is any XML document which follows the rules described in the previous section. However this is not sufficient in some cases. Inside an XML document you can have any XML tag you can imagine. This is not harmful to XML itself but makes it impossible to process such a document with a computer program and makes it very hard to maintain the program to keep it synchronised with all the new tags users invent. For a well formed XML document is not possible to check or validate that the document contains only the tags which make sense or have valid content. For that purpose there exists a notation called Document Type Definition (DTD) which comes from SGML world. This notation permits the definition of a grammar (a valid set of tags, their contents and attributes) which allows then to perform the validation of XML documents, i.e. whether the document contains the XML tags which belong to the set of tags defined by its associated DTD. In addition, the validating application can check whether the tags contain only allowed tags or text data, and whether the tags use only attributes defined for them by the DTD. The validation process can can also perform normalization of attributes, i.e. assign default values to attributes that the user has omitted because they are described as optional or with a fixed value in the DTD.
Important note: the default behaviour of the validating application, recommended by the XML standard, is to stop parsing of an XML document in case of an error. This is because the XML files describe data and an error in XML means corrupted data.
In this section we describe how to create or update the XML data files used by the detector description database. We will go through all available XML elements defined for the detector description, explain their XML syntax and show how to use them. For convenience we have included pseudo UML diagrams showing content model definitions of the XML tags. This approach has been chosen because it is easier to understand the graphical form than raw DTD definitions. Here follows a brief explanation how to read these pseudo UML diagrams:
|
Diagram notation
|
DTD notation
|
Description
|
|---|---|---|
|
Type
|
Description
|
|---|---|
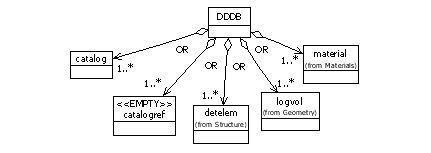
To fulfil the XML basic rule that each XML document must have only the one root XML element we have defined the element DDDB, see Figure 11.
|
This element must be present in each of the XML files created for the detector description. This element is so defined that it can contain all the important elements needed for detector description and thus the database can be spread over multiple XML files. The
DDDB
element can contain one or more of the following elements: catalog, catalogref, detelem, logvol, material. Each of these elements will be described in detail later
The detector description in XML requires a bootstrap file which contains a definition of the database root and a definition of the top level catalogs mentioned above. This done in a flexible way to make it possible to have multiple bootstrap files. This can be done in the job options by setting the application manager properties DetDbLocation and DetDbRootName. They allow to switch from one bootstrap file to another and to switch between root nodes. The bootstrap file must have defined the root node catalog as the only child of the
DDDB
element. Inside the root node catalog the top level catalogs can be defined according to the required content. See Listing 23 for an example.
In the example, the root nodes catalog /dd and its three top level catalogs for logical detector description, geometry and materials are defined. Note that the
catalog
and
catalogref
tags have not specified the classID attribute. This shows how the validation can reduce the amount of the text in XML because these values are automatically included after the document has been validated against the DTD file structure.dtd specified in the DOCTYPE section.
The catalog and catalogrefs are used as bookshelves or references to bookshelves respectively to achieve a possibility to split the XML database into logical partitions. The catalogref element acts as forward reference saying where to find the given catalog definition. This tag is one of the XML references defined for the detector description. All of them have almost the same usage and syntax. The common things they have are attributes for class ID and hyperlink reference. The difference is the value of the class ID of the objects they point to, also some of them may contain other elements. The hyperlink is in general specified using the format:
protocol://hostname/path/to/the/file.xml#ObjectID or #ObjectID
The protocol and hostname parts can be omitted if the file resides on the local host. It is possible to write a hyperlink without the full path name in case one needs to refer to an XML object residing inside another file. In this case the relative path will be appended to the location of the currently parsed XML file.
For example having the current file location /full/path/to/current.xml and inside this file a hyperlink as href="next/file.xml#NextOID" the hyperlink will be resolved as /full/path/to/next/file.xml#NextOID.
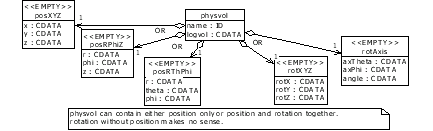
If the hyperlink has the form #ObjectID this means that the referred object is located in the same file. For content model definitions of the catalog and catalogref elements see Figure 12

|
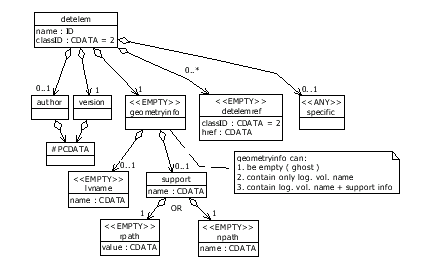
Figure 13 shows the content model definition of the detelem element and its child elements.
|
The detelem element has a sequence of tags which must appear in the same order shown on the diagram (
author, version, geometryinfo, detelemref, specific
). The child elements author, detelemref and specific are optional so if they are not present the content is still valid. The #PCDATA stands for "parsed character data" which is text4.
Listing 24 shows the XML definition of the Vertex detector containing the author of this definition, the version, geometry information about the associated logical volume and two sub-detectors of the LHCb detector.
The example shows that the definition of the VertexStation sub-detectors can be found in the file vertex.xml. The standard class ID for detector element is 2, but here the class ID is set to 9999, which means that this sub-detector is customized by the user and contains specific information, in which XML tags to describe specific features the detector have been defined by the user. The customizing of detector elements is described in section 8.5.3.
The geometryinfo element definition says that the Vertex detector has an associated logical volume with the given name on the transient store. The logical volume should be defined somewhere else in the XML and is retrieved automatically when the user asks for it via the IGeometryInterface returned by the geometry() accessor method. There two more tags in the geometryinfo definition. They are supporting detector element and its replica path. The supporting detector element is one of the parent detector elements sitting on the same branch in the logical detector description hierarchy. It can be a direct parent or a detector element 3 levels up. Its role is to help in finding of physical volume location in the geometry hierarchy for the detector element which is referring to it. The replica path is a sequence of numbers which is used by the algorithm looking for the physical volume location in the geometry hierarchy. This sequence is composed of the number of daughter volume IDs which must be followed from a logical volume of supporting detector elements down through the hierarchy. If it is in numeric form (rpath) then it must start counting from 0. If it is in the literal form (npath) it can be a text label but it must be unique inside the mother logical volume where it is defined and used. This label is internally converted into its proper numeric equivalent at run-time.
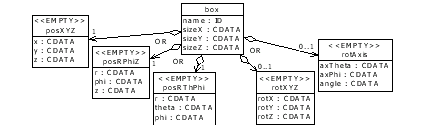
To define a logical volume in XML the logvol element is used, see Figure 14.

|
The complete logical volume definition includes the name of the logical volume, its material, its class ID (may be omitted, because the DTD defines its fixed value), its solid (shape) and list of daughter volumes represented by physical volumes or parametric physical volumes. The content model definitions of physical and parametric physical volumes is shown in Figure 15 and Figure 16. The diagram in Figure 14 shows all attributes for solids. Figure 17 and Listing 26 show how to define solids. Listing 25 shows an example of a logical volume in XML.
|

|
The example shows two logical volumes lvLHCb and lvVertex. The former volume is made of the material Vacuum and its solid is defined as a box with dimensions 50 x 50 x 60 meters. Then it has ascribed one daughter volume lvVertex positioned inside the lvLHCb volume without rotation and shifted along the z-axis by 200 millimetres. The lvVertex volume is made of material Silicon and its shape is defined by the solid tubs (cylinder) and has one parametric physical volume which places 6 daughter volumes of lvVStation.
The initial position of the first daughter volume is placed 200 millimeters backwards along the Z axis relative to the center ofthe lvVertex mother volume. The remaining daughter volumes are then shifted by 50 millimeters along Z axis one by one relative to the previous one without rotation.
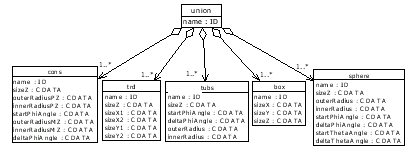
Simple solids are based on the concept of Constructive Solid Geometry (CSG). This concept is nothing new, it has been used already by GEANT3 and Geant4 and by the other frameworks. There are defined the solids of the basic 3D volumes such as sphere, box, cylinder, conus, toroid...
The solid definition is fundamental property of a logical volume object and thus is needed to capture this information inside XML as well. For that purpose there are defined the XML tags for the solids of the basic 3D volumes such as sphere, box, cylinder, conus, toroid... The diagram in Figure 17 shows the content model definition of the simple solids. An example of XML is shown in Listing 26. Note that simple solids canott contain position and rotation definitions in the context of logical volume. When used inside logical volume the transformation makes no sense. On the other hand when used in the context of boolean solids the transformation tags are needed in order to specify the position of the solids according to each other.
|
The current implementation allows to create boolean solids as a union, intersection or subtraction of several simple solids. The content model is shown in Figure 18
|
The user has to start with the so called main solid and all the other solids participating in the boolean solid are positioned relative to the main solid. In this context the position and rotation attributes of solids are applied together with their dimensions attributes. Listing 26 shows how to create a simple union of solids.
The example shows the union of two boxes where the first one is the main solid and the second one is positioned just next to the main solid along the z-axis.
Material is another important attribute of the logical volumes. Materials can be defined as isotopes, elements or mixtures. The elements can be optionally composed of isotopes. Mixtures can be composed of elements or of other mixtures. Composition of elements is done always by specifying the fraction of the mass for each of the isotopes of the element. For a mixture the user can specify either composition by number of atoms of by fraction of the mass for each of the elements or mixtures. It is not allowed to mix composition by fraction of the mass and by atoms inside the same definition of a mixture.The XML code listings 27, 28, 29 and 30 show how to define Gaudi isotopes, elements and material compounds and mixtures in XML
The specific detector description can be made available to algorithms by customizing the generic detector element. Customizing is done by inheriting the specific detector class from the generic DetectorElement. The sub-detector specialist can provide specific answers to algorithms based on a combination of common parameters (general geometry, material etc.) and some specific parameters. For example, an algorithm may want to know what are the coordinates of a given cell or wire number in the local reference system. The specialist can "code" the answer by using a minimal number of parameters specific to the detector structure.
This means providing the C++ definition of your specific detector module, as shown in Listing 31. The actual implementation of all the methods is done inside MyDetector.cpp file.
At first the user must obtain the unique class ID for his/her own detector element type. The class ID is needed for conversion service and the corresponding converter. The methods returning the class ID must be supplied exactly as shown in the example.
The example shows further that the new detector element type will have its specific data, e.g. detector cell size. For this information we will create a user defined XML tag inside the <specific> section of detector element XML tag, see the next step.
In this step one needs to define all the new XML tags for the detector element specific data that the user wants to access from the XML data file. The definition of the new XML tags is done inside the, so called, local DTD section. This is needed validation purposes. With this definition, the XML parser is then able check whether the syntax of the user defined XML tags is valid or not. The next step is to provide information about the geometry. Actually here we do not do the full geometry description, but only create the association telling the converter where to look for full geometrical information about this detector element. The definition of the geometry is shown at the next step. Finally the user has to define sub detectors or sub modules if any. An example XML definition of the MyDetector element type is shown in Listing 32, in which two new XML tags are defined: AluminiumPlateThickness and CellSize. They are the used inside the <specific> section filled with the concrete data
The CellSize tag is defined as an empty tag with one attribute "n". The tag AluminiumPlateThickness has no attribute but has content. In step 4 we will show how properly retrieve information out if these tags by methods of a user defined XML converter.
In the previous step the association to the geometry has defined, but the actual geometry does not exist yet. This step will fill the gap by providing all the needed information in XML.
First we define the catalog of all the logical volumes of MyDetector, as shown in Listing 33. This catalog is accessible at run-time as /dd/Geometry/MyDetector. Such a catalog allows modification of the XML detector description database by many people in parallel, because all the changes to the geometry structure inside this catalog can be kept local to this catalog without affecting the other subdetectors. It also makes the structure on the transient store more clear and similar to the logical structure of the detector. The catalog contains only references to logical volumes defined in the same file.
Next we have defined the logical volume for our
MyDetector
element with its shape as box and 3 daughter volumes. The first two daughter volumes are represented by parametric physical volume and the third one by normal physical volume.
The definition of the remaining two logical volumes is missing from Listing 33, but these are defined in a similar way to the one shown.
As a first step we need to create instance of the user level XML converter for MyDetector element type. This done by inheritance from XmlUserDeCnv<> templated class which is parametrized by our MyDetector element type, see Listing 34..
What is important here is to define the corresponding converter factory otherwise this converter will not be invoked.
As the next step is actual implementation of the callbacks of the IUserSax8BitDocHandler interface. This interface is defined as shown in Listing 35.
The names of the methods are self descriptive but two of them may need more detailed explanation. The methods uIgnorableWhitespace and uCharacters are called for #PCDATA contents of an XML tag. The reason why there are two methods instead of one is that the XML specification says that white characters inside XML documents are preserved and the decision is left up to the application which should either ignore them or process them.
Let us move back to writing our XML converter. The uStartElement is called always when XML parser jumps onto the next XML tag inside the <specific> section. The implementation of this callback is shown in Listing 36.
There is a clear action there for the tag CellSize. We get the value of the attribute "n" by name and we evaluate its content by numerical expressions parser with checking for CLHEP units enabled and finally we set the m_cellSize property of our detector element.
For the tag AluminiumPlateThickness, however, we can't do much at this this time because its content has not been parsed yet. What we do here is initialization of the static variable used to collect all of the characters inside the content of the AluminiumPlateThickness tag.
Listing 37 shows how we process #PCDATA content of our XML tag by collecting all of the characters and inside the uEndElement callback we finally evaluate the string expression we have collected and set the corresponding property of our detector element.
This is a simple parser for evaluation of numerical expressions. It is available for Gaudi framework converters as well as for the user defined converters. The only difference is that in user defined converters the parser is not instantiated explicitly by the user but is accessed through the IXmlSvc interface instead. See Listing 37 for an example of its use.
The numerical expressions recognized by the parser can be composed of integers and floating point numbers assuming one of the formats:
Supported operations are: + - * / unary +|- exponent ^
Parenthesized expressions: 1.4 * (23.4-e12 / 1.8)
Operator precedence is: () unary +|- ^ *|/ +|-
In addition, the parser understands CLHEP units. The result is always evaluated to double value. The check for the presence of CLHEP units inside expressions is enabled by default. To suppress this behavior the call of the eval() method must look like:
This is a tool provided to edit the XML files of the detector description database without having to learn the XML syntax. It is provided as a separate Gaudi package and was written in Java.
The installation of XmlEditor is similar to that of any Gaudi package. It uses CMT in the same way and compiles and runs both under Windows and Linux.
The only trick is the way you run the application. The package actually contains a "script" subdirectory where two executables are located : "xmlEditor" and "xmlEditor.bat", the first running under Linux and the second under Windows. You just have to launch one of them after compilation of the package.
Note that you must provide a Java runtime environment to use XmlEditor. This has to be version 1.2.2 or later. It wasn't actually tested on other versions of Java. Anyway, the javax.swing facilities must be provided.
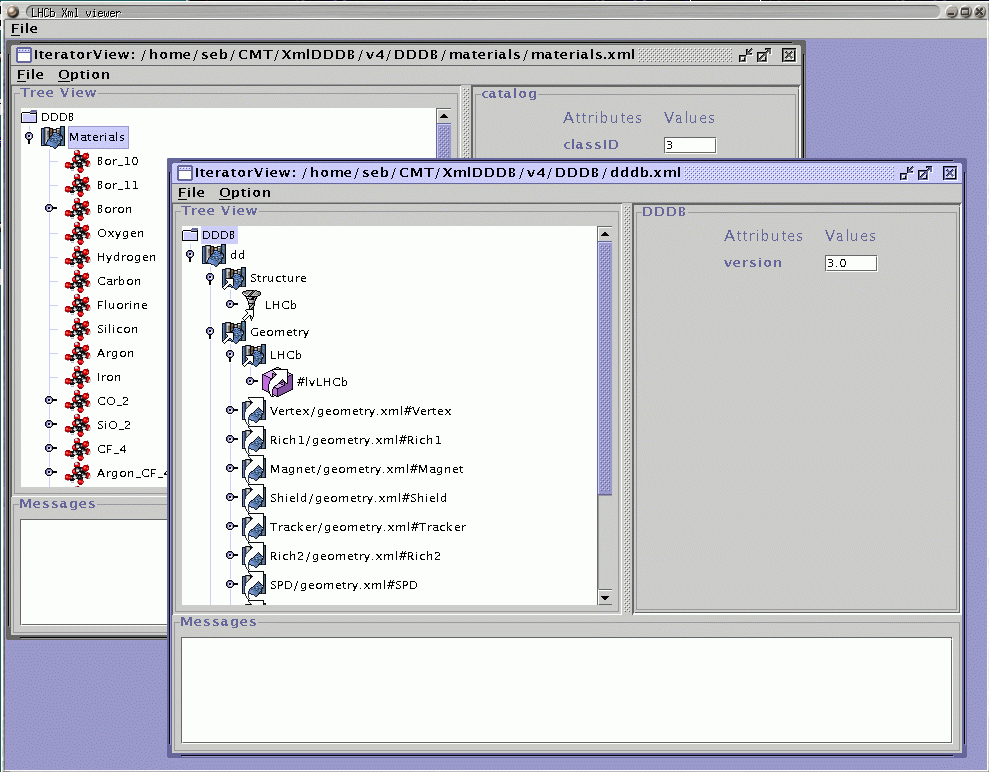
XmlEditor is an Explorer like application that is able to display an XML document as a tree. Each node of this tree represents an element in the XML document. A snapshot of the GUI of the XmlEditor is shown in Figure 19.
|
The menu of the main window is very simple : you can only open a new XML file, close all opened files or save them all. You can of course open several files and edit them at the same time.
When working on a file, basic functionalities are very similar to those of Explorer : double click to open or close a node, click to select it, click to edit it when selected and so on. The drag and drop functionnalities are not implemented at this time but will be in the next version. The content of the node, i.e. its attributes, are displayed for the selected node on the right of the screen. Every attribute is editable.
Besides that, some specificities of the detector description have been taken into account. First, you can see that most of the important elements (detector element, logical volumes, catalogs and materials) have a specific icon that allows the user to distinguish them easily. Then, the detector description XML uses references across files via tags like
<catalogref>
. These are also taken into account. When a reference is displayed, it is not dereferenced by default, in order not to load the whole detector description database in every case. It is displayed using a special icon (the one of the normal object plus an arrow on the top). If the user wants to dereference it, he can double click on it and the corresponding file will be loaded and displayed. Even when dereferenced, a reference keeps a specific icon (the normal one plus a little arrow on top). The different icons used for a catalog are shown in Figure 20.
|
|
|
|
The "Option" menu gives some possibilities :
In such a case, the selection of the "Value as attribute" option will make the text node containing "Smith" appear as an attribute of the node author with "Value" as attribute name.
In such a case, the user can choose to make the "author" node appear as an attribute of the "detelem" node. He does that by checking the corresponding box in the second column of the "SubElement Displaying" dialog.
The current release of the XmlEditor (ie the first release) does not provide many editor functionalities. Briefly, you can change everything existing in the file you are looking for but you cannot create anything new.
You can edit what exists in the Explorer like way : click on the content you want to edit when it is selected.
Just take care when you are editing nodes that use entities. You can notice that these are expanded in the XmlEditor. This means that a modification will remove the use of the entity to replace it by the value displayed. This will change in the next release.