Appendix D
Design considerations
D.1 Generalities
In this chapter we look at how you might actually go about designing and implementing a real physics algorithm. It includes points covering various aspects of software development process and in particular:
· The need for more "thinking before coding" when using an OO language like C++.
· Emphasis on the specification and analysis of an algorithm in mathematical and natural language, rather than trying to force it into (unnatural?) object orientated thinking.
· The use of OO in the design phase, i.e. how to map the concepts identified in the analysis phase into data objects and algorithm objects.
· The identification of classes which are of general use. These could be implemented by the computing group, thus saving you work!
· The structuring of your code by defining private utility methods within concrete classes.
When designing and implementing your code we suggest that your priorities should be as follows: (1) Correctness, (2) Clarity, (3) Efficiency and, very low in the scale, OOness
Tips about specific use of the C++ language can be found in the coding rules document [6] or specialized literature.
D.2 Designing within the Framework
A physicist designing a real physics algorithm does not start with a white sheet of paper. The fact that he or she is using a framework imposes some constraints on the possible or allowed designs. The framework defines some of the basic components of an application and their interfaces and therefore it also specifies the places where concrete physics algorithms and concrete data types will fit in with the rest of the program. The consequences of this are: on one hand, that the physicists designing the algorithms do not have complete freedom in the way algorithms may be implemented; but on the other hand, neither do they need worry about some of the basic functionalities, such as getting end-user options, reporting messages, accessing event and detector data independently of the underlying storage technology, etc. In other words, the framework imposes some constraints in terms of interfaces to basic services, and the interfaces the algorithm itself is implementing towards the rest of the application. The definition of these interfaces establishes the so called "master walls" of the data processing application in which the concrete physics code will be deployed. Besides some general services provided by the framework, this approach also guarantees that later integration will be possible of many small algorithms into a much larger program, for example a reconstruction program. In any case, there is still a lot of room for design creativity when developing physics code within the framework and this is what we want to illustrate in the next sections.
To design a physics algorithm within the framework you need to know very clearly what it should do (the requirements). In particular you need to know the following:
· What is the input data to the algorithm? What is the relationship of these data to other data (e.g. event or detector data)?
· What new data is going to be produced by the algorithm?
· What's the purpose of the algorithm and how is it going function? Document this in terms of mathematical expressions and plain english.1
· What does the algorithm need in terms of configuration parameters?
· How can the algorithm be partitioned (structured) into smaller "algorithm chunks" that make it easier to develop (design, code, test) and maintain?
· What data is passed between the different chunks? How do they communicate?
· How do these chunks collaborate together to produce the desired final behaviour? Is there a controlling object? Are they self-organizing? Are they triggered by the existence of some data?
· How is the execution of the algorithm and its performance monitored (messages, histograms, etc.)?
· Who takes the responsibility of bootstrapping the various algorithm chunks.
For didactic purposes we would like to illustrate some of these design considerations using a hypothetical example. Imagine that we would like to design a tracking algorithm based on a Kalman-filter algorithm.
D.3 Analysis Phase
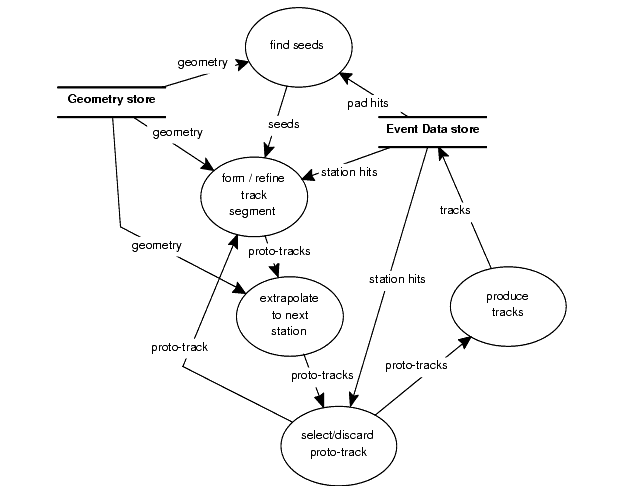
As mentioned before we need to understand in detail what the algorithm is supposed to do before we start designing it and of course before we start producing lines of C++ code. One old technique for that, is to think in terms of data flow diagrams, as illustrated in Figure A.1, where we have tried to decompose the tracking algorithm into various processes or steps.
Figure A.1 Hypothetical decomposition of a tracking algorithm based on a Kalman filter using a Data flow Diagram
In the analysis phase we identify the data which is needed as input (event data, geometry data, configuration parameters, etc.) and the data which is produced as output. We also need to think about the intermediate data. Perhaps this data may need to be saved in the persistency store to allow us to run a part of the algorithm without starting always from the beginning.
We need to understand precisely what each of the steps of the algorithm is supposed to do. In case a step becomes too complex we need to sub-divide it into several ones. Writing in plain english and using mathematics whenever possible is extremely useful. The more we understand about what the algorithm has to do the better we are prepared to implement it.
D.4 Design Phase
We now need to decompose our physics algorithm into one or more Algorithms (as framework components) and define the way in which they will collaborate. After that we need to specify the data types which will be needed by the various Algorithms and their relationships. Then, we need to understand if these new data types will be required to be stored in the persistency store and how they will map to the existing possibilities given by the object persistency technology. This is done by designing the appropriate set of Converters. Finally, we need to identify utility classes which will help to implement the various algorithm chunks.
D.4.1 Defining Algorithms
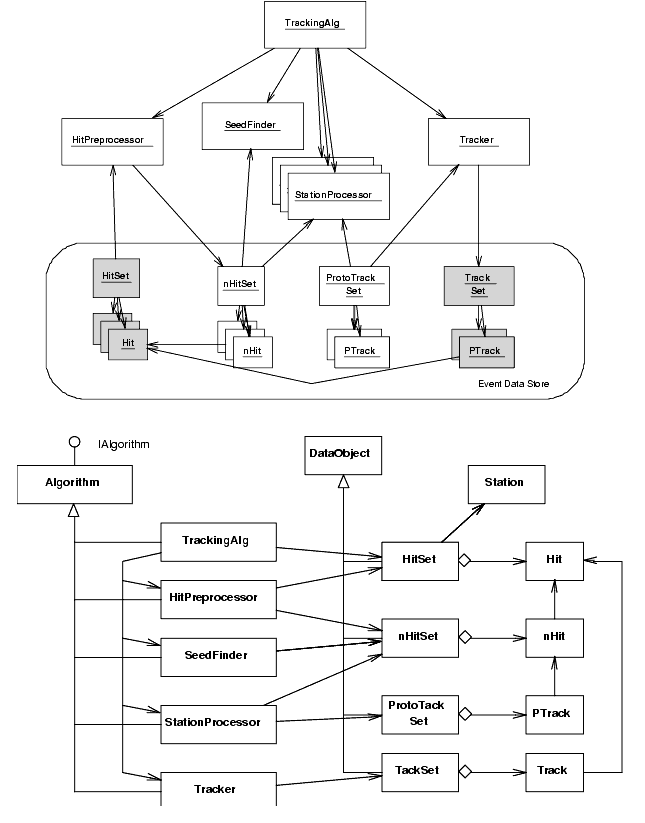
Most of the steps of the algorithm have been identified in the analysis phase. We need at this moment to see if those steps can be realized as framework Algorithms. Remember that an Algorithm from the view point of the framework is basically a quite simple interface (initialize, execute, finalize) with a few facilities to access the basic services. In the case of our hypothetical algorithm we could decide to have a "master" Algorithm which will orchestrate the work of a number of sub-Algorithms. This master Algorithm will be also be in charge of bootstraping them. Then, we could have an Algorithm in charge of finding the tracking seeds, plus a set of others, each one associated to a different tracking station in charge of propagating a proto-track to the next station and deciding whether the proto-track needs to be kept or not. Finally, we could introduce another Algorithm in charge of producing the final tracks from the surviving proto-tracks.
It is interesting perhaps in this type of algorithm to distribute parts of the calculations (extrapolations, etc.) to more sophisticated "hits" than just the unintelligent original ones. This could be done by instantiating new data types (clever hits) for each event having references to the original hits. For that, it would be required to have another Algorithm whose role is to prepare these new data objects, see Figure A.2.
The master Algorithm (TrackingAlg) is in charge of setting up the other algorithms and scheduling their execution. It is the only one that has a global view but it does not need to know the details of how the different parts of the algorithm have been implemented. The application manager of the framework only interacts with the master algorithm and does not need to know that in fact the tracking algorithm is implemented by a collaboration of Algorithms.
D.4.2 Defining Data Objects
The input, output and intermediate data objects need to be specified. Typically, the input and output are specified in a more general way (algorithm independent) and basically are pure data objects. This is because they can be used by a range of different algorithms. We could have various types of tracking algorithm all using the same data as input and producing similar data as output. On the contrary, the intermediate data types can be designed to be very algorithm dependent.
The way we have chosen to communicate between the different Algorithms which constitute our physics algorithm is by using the transient event data store. This allows us to have low coupling between them, but other ways could be envisaged. For instance, we could implement specific methods in the algorithms and allow other "friend" algorithms to use them directly.
Concerning the relationships between data objects, it is strongly discouraged to have links from the input data objects to the newly produced ones (i.e. links from hits to tracks). In the other direction this should not be a problem (i.e from tracks to constituent hits).
For data types that we would like to save permanently we need to implement a specific Converter. One converter is required for each type of data and each kind of persistency technology that we wish to use. This is not the case for the data types that are used as intermediate data, since these data are completely transient.
D.4.3 Mathematics and other utilities
It is clear that to implement any algorithm we will need the help of a series of utility classes. Some of these classes are very generic and they can be found in common class libraries. For example the standard template library. Other utilities will be more high energy physics specific, especially in cases like fitting, error treatment, etc. We envisage making as much use of these kinds of utility classes as possible.
Some algorithms or algorithm-parts could be designed in a way that allows them to be reused in other similar physics algorithms. For example, perhaps fitting or clustering algorithms could be designed in a generic way such that they can be used in various concrete algorithms. During design is the moment to identify this kind of re-usable component or to identify existing ones that could be used instead and adapt the design to make possible their usage.
1 Catalan is also acceptable.
|
Quadralay Corporation http://www.webworks.com Voice: (512) 719-3399 Fax: (512) 719-3606 sales@webworks.com |