Chapter 8
Detector Description
8.1 Overview
In this chapter we describe how we make available to the physics application developed using the framework the information related to the detector that resides in the detector description database (DDDB). The DDDB is the persistent storage for all the versions of the detector data needed to describe and qualify the detecting apparatus in order to interpret the event data.
The final clients of the detector description are the algorithms that need this information in order to perform their job (reconstruction, simulation, etc.). To provide this information, there needs to be a sub-detector specific part that understands the sub-detector in question and uses a set of common services. The detector description we are providing in Gaudi is nothing else than a framework for developers to provide the specific detector information to algorithms by using as much as possible common or generic services. A brief introduction to this framework can be found in reference [9].
In the following sections we begin with an overview of the DDDB. We then discuss how to access the detector description data in the Gaudi transient detector data store. This is followed by a discussion of the features of the Gaudi detector description and of its structure. We then describe in detail how the detector description can be built and made persistent using the XML markup language and continue with an introduction to an XML editing tool which allows browsing and modification of the DDDB. Finally we describe some features of the so called Conditions Database, where the time-dependent elements of the DDDB can be stored.
8.2 Detector Description Database
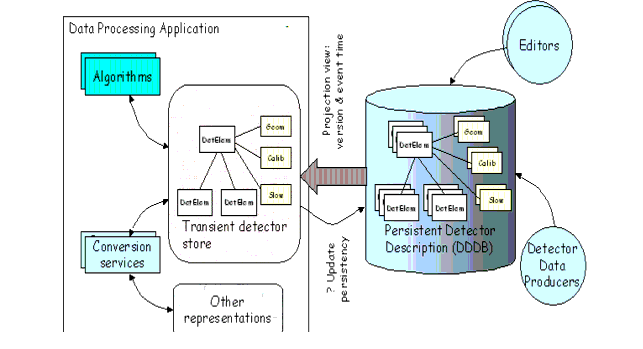
The detector description database (DDDB), see Figure 8.1, includes a physical and a logical description of the detector. The physical description covers dimensions, shape and material of the different types of elements from which the detector is constructed. There is also information which corresponds to each element which is actually manufactured and assembled into a detector, for example the positioning of each element. Both active and passive elements should be included. The description of active elements should allow for the specification of deficiencies (dead channels), alignment corrections, etc. and also detector response characteristics, e.g. energy normalization in calorimeters, drift velocity in gas chambers.
Figure 8.1 Overview of the Detector Description model.
The logical description provides two main functions. The first is a simplified access to particular parts of a physical detector description. This could be a hierarchical description where a given detector setup is composed of various sub-detectors, each of which is made up of a number stations, modules or layers, etc. and there would be a simple way for a client to use this description to navigate to the information of interest. The second function of the logical description is to provide a means of detector element identification. This allows for different sets of information which are correlated to specific detector elements to be correctly associated with each other
In a detector description, the definition of the detector elements and of the data associated to their physical description may vary over time, for instance due to real or hypothetical changes to the detector. Each such change should be recorded as a different version of the detector element. Additionally, it should be possible to capture, for an entire description, a version of each of the elements and to associate a name to that set. This is similar to the way CVS allows one to tag a set of files so that one does not need to know the independent version numbers for each file in the set.
The present version of the DDDB includes only the logical description of the detector and the physical description of its geometry and all required materials. This information is described using the XML language and stored in XML text files. The rest of the time varying "detector condition" data (alignment, calibration, readout, slow control and fast control) will eventually be stored in the so called Conditions Database. This database is meant to record the validity range of each data element, allowing algorithms to process events using the detector description data valid at the given event time. Some features of the Conditions Database are described in Section 8.6.
8.3 Detector Data Transient Store
8.3.1 Structure of the transient store
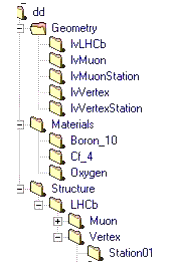
The transient representation of the detector description is implemented as a standard Gaudi data store. Refer to Chapter 6 for general information on how to access data in stores. The structure of the detector transient store is represented in Figure 8.2.
Figure 8.2 The structure of part of the LHCb detector data transient store.
In the present production version of the DDDB (package Det/XmlDDDB) there are three top level catalogs in the transient store. The main catalog, called "Structure" contains the logical structure of the detector identified by the "setup name" i.e. "LHCb" containing the description of the detector and this catalog is used for identification and navigation purposes. Other catalogs are the palette of logical volumes and solids, called "Geometry", used for the geometry description and the palette of materials, called "Materials", used to describe the material properties of the solids needed for the detector simulation, etc.
Five more top level catalogs are foreseen in the transient store as palettes for the additional time varying information about the detector. The "Alignment" catalog will contain the geometrical data coming from regular surveys and necessary to determine the precise position of each subdetector. The "Calibration" catalog should be used to store the list of dead channels and the response parameters of each subdetector, such as energy normalization in calorimeters and drift velocity in gas chambers, while the "Readout" catalog is meant to contain the mapping of active detector elements to readout channels. Finally, the "SlowControl" and "FastControl" catalogs will be used to store, respectively, online measurements of quantities such as pressures and temperatures, and information about the fast control system. A prototype implementation of this extended transient detector store can be found in package Ex/DetCondExample.
8.3.2 Accessing detector data
An algorithm that needs to access a given detector part uses the detector data service to locate the relevant DetectorElement. This operation can be generally done during the initialization phase of the algorithm. Contrary to the Event Data, the Detector Data store is not cleared for each event and the references to detector elements remain valid and are updated automatically during the execution of the program. Locating the relevant detector element is done using the standard IDataProviderSvc interface via the detSvc() accessor as shown in Listing 8.1
Remember that data are only loaded on demand, when they are used for the first time. The test on vertex not only tests if the data are present but also ensures that the data are loaded.1
The user can retrieve an array of references to detector elements in a similar way. The code in Listing 8.2 can be used to prepare an array with pointers to all of the Muon stations. Here we use an STL vector of pointers to DeMuonStation objects to store the retrieved Muon stations.
Once more, don't forget to test each DataObject. Also note that you are not obliged to retrieve DetectorElements, you can actually retrieve whatever object inherits from it, provided that the corresponding converter exists (see Section 8.5 for a discussion on the persistent representation and converters). Here some DeMuonStations are converted
8.3.3 Using the DetectorElement class
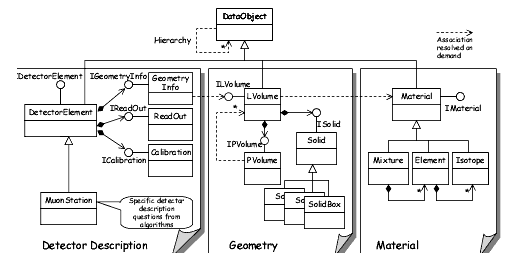
The DetectorElement class implements the IDetectorElement interface, as shown in Figure 8.3.
Figure 8.3 Simplified class diagram for the transient detector description
This interface offers six accessor methods to the different types of condition data for each detector element: geometry(), alignment(), calibration(), readOut(), slowControl() and fastControl(). In addition, DetectorElement implements the IValidity interface. This interface is used to check if the detector element is synchronized with the current event. If the detector element is no longer valid at the time the current event was generated, the corresponding DataObject in the Structure tree of the transient store must be updated from the persistent storage. In the current implementation it is not foreseen for end users to use this interface directly.
The accessor method geometry() gives access to geometry information offered by the interface of type IGeometryInfo. This interface allows the retrieval of a reference to a logical volume associated with the given detector element, its material property, the position in the geometrical hierarchy. In addition to that you can ask it questions like:
1. Transformation matrix from the Global to the Local Reference system
2. Transformation matrix from the Local to the Global Reference system
3. Perform transformation of point from the Global to Local Reference system
4. Perform transformation of point from the Local to Global Reference system
5. Name of daughter volume (of current volume) which contains given (global) point
6. Get a pointer to daughter volume which contains given (global) point
7. Name of daughter volume (at deeper hierarchical level) which contains given point
8. Get a pointer to daughter volume (on deeper level) to which contains given point
9. Get the exact full geometry location2
10. Whether the given point is inside the associated logical volume or not
11. A pointer to the associated logical volume
As an example, the code fragment in Listing 8.3 shows how to obtain a number of geometrical objects from a given detector element:
The remaining five accessor methods to the condition information of a detector element return pointers to the five corresponding interfaces of type IAlignment, ICalibration, IReadOut, ISlowControl and IFastControl, respectively. In the present implementation of the detector description package Det/DetDesc, these interfaces are much simpler than IGeometryInfo and do not yet offer specialized methods to handle the data they refer to. In particular, they are presently all equivalent to the interface from which they are derived, IConditionInfo, a simple interface which allows to retrieve a pointer to one "Condition" data object, containing all relevant condition data of the given type. Each Condition data object is meant to be loaded in the corresponding tree of the detector transient store: for instance, the slow control condition for Ecal may be be stored in /dd/SlowControl/Ecal/scEcal, just like the main logical volume for Ecal is stored in /dd/Geometry/Ecal/lvEcal.
A Condition is simply a DataObject implementing the IValidity and IUserParameter interfaces. It contains an arbitrary number of user-defined parameters and parameter vectors, taking numerical or string values and identified by their names, which can be retrieved through the IUserParameter interface. The IValidity interface deals with the validity range of a Condition object, allowing it to be updated when it becomes invalid.
As an example, the code fragment in Listing 8.4 shows how to retrieve and print the parameters of the alignment Condition for a given detector element. Remember that also Conditions, like all other DataObjects, are only loaded on demand, when they are used for the first time: the test on alEcal not only tests if the data are present but also ensures that the data are loaded. Eventually, the framework will also take care to automatically keep up-to-date all Condition objects used by the algorithms; this is discussed more in detail in Section 8.6. The test on ecalAlignmentInfo, instead, is only necessary because a valid pointer to an IAlignment interface is currently retrieved only for those DetectorElements for which a test version of the alignment information has been defined.: 8.3.4 Extending the DetectorElement class
As you can see in Listing 8.2, the transient store allows you to retrieve either DetectorElement objects or your own object, extending DetectorElement.The definition of your objects is fully free as you can see in Listing 8.5.
There are a few important things to know here :
· you have to define a new classID for the new object. This one must be unique and will be used to distinguish this object from the default DetectorElement. ClassIDs can be requested using the same procedure as for event data, as described at http://cern.ch/lhcb-comp/Frameworks/EventModel/CLID.htm.
· the usage of a new object instead of the default DetectorElement supposes that the user writes a new converter for this new object. This is described in a dedicated document : "Extending detector elements and implications", by Sebastien Ponce, available at http://cern.ch/lhcb-comp/Frameworks/DetDesc/Documents/detElemExtension.pdf.
· the new object, as extension of DetectorElement, has an initialize method. This method is called by the conversion service at the end of the object creation, when every contained object has been computed. This is the place where some computation could be done. Once more, see the dedicated document for further details and examples.
8.3.5 Configuring the Gaudi framework to access the detector description
Applications accessing the detector description have to provide a number of job options to the framework. For convenience, these have been collected together in the file DetDesc.opts of the GaudiConf package. The user simply needs to add the line below to his job options file:
#include "$STDOPTS/DetDesc.opts"
In addition, the application must use a number of CMT packages, as shown below,
use DetDesc v7 Det
use XmlDDDB v6r1 Det
Package Det/XmlDDDB contains the XML files for the production version of the persistent DDDB, including all detector elements with their geometry and materials, while package Det/DetDesc contains the DetectorElement class and all generic XML services and converters. Of course, any sub-detector specific packages containing the sub-detector specific converters should also be used, with the corresponding job options for loading the sub-detector specific DLLs.
8.4 General features of the detector description
As explained in Section 8.3.1, the detector description is divided into three main parts, Structure, Geometry and Materials. We describe here the features and meaning of the elements present in each of these parts. Five other catalogs are also foreseen for Alignment, Calibration, ReadOut, SlowControl and FastControl, although these are not present in the current production version of the DDDB. A brief description of these catalogs is also given.
8.4.1 Structure
The structure of the detector is described as a tree of detector elements. These could also be user defined types that inherit from the class DetectorElement.
Each node of the tree, being a detector element, has the following characteristics:
· a class identifier : this tells the framework which converter should be used for this element.
· a geometry info object where all its geometry is described
· five additional condition info objects allowing to access and manipulate its alignment, calibration, readout, slow control and fast control data
· a set of user parameters, each one defined by a name, a comment, a type and a value
8.4.2 Geometry
The geometry in the Gaudi detector description is a bit more than just solids and surfaces. It has to include a way of structuring the geometry in order to avoid repetitions and to facilitate the placement of subparts into their parents.
After giving some general considerations concerning the description of the geometry, we describe here the two classes LVolume and PVolume that build the structure of the geometry. Finally, solids and surfaces are quickly described.
You can find more information in the Gaudi web pages, especially at http://cern.ch/lhcb-comp/Frameworks/DetDesc/default.htm, in the "Detector geometry model" section.
8.4.2.1 General considerations
The Gaudi geometry description was based on some postulates :
· The geometry is a tree of volumes, where each child describes a subpart of its parent volume.
· There are no "up-links" in the geometry tree. This means that each volume has no information about its parent's volume. Of course, each volume has information about its children.
· No volume has any information about its absolute position. The only spatial information in the whole tree is local: each volume is placed into its parent.
· The geometry (description of shapes and surfaces) and material information is kept by each volume via a Solid, a Surfaces and a Material object. Thus the information can be retrieved at several levels: the top-most volume may contain a global shape and an average material and the leaves of the tree contain the most precise material and geometry.
· All boolean operations on volumes are strictly forbidden3. Boolean operations should be performed at the level of Solids. This is one of the most essential postulates of the Gaudi geometry structure.
The geometry tree which fulfils all these postulates represents a very effective, simple and convenient tool for description of the geometry. Such a tree is easily formalized. It has many features which are similar to the features of the geometry tree used within the Geant4 toolkit and could easily be transformed to the Geant4 geometry description.
Some consequences of these postulates are:
· The top-level volume (presumably the experimental hall, or cave, or the whole LHCb detector) defines the absolute coordinate reference system. In other words, the null-point (0,0,0) in the so called Global Reference System is just the center of the top volume.
· All geometry calculations, computations, inputs and outputs, performed with the usage of a volume are in the local reference system of this volume.
Sometimes one needs a more efficient way of extracting information from the geometry tree or to compute the unique location of a point in the geometry tree. For these purposes, a simplified detector description tree is introduced into the Gaudi framework4.
8.4.2.2 LVolume and PVolume
Up to now, we only talked about volumes. This term is mapped to a class called LVolume which stands for Logical Volume. In this class, you can find a Solid describing the shape of the volume, a list of Surfaces associated to it and the Material of the volume.
On top of that, LVolume is an identifiable object and therefore inherits from class DataObject and can be identified in the transient data store by a unique name (its "path" in the geometry tree). It implements the ILVolume and IValidity interfaces.
As we said before, this LVolume has a set of children. These are actually PVolumes, which stands for Physical Volume but should stand for Placed Volume. The notion of Physical Volume in the Gaudi geometry is extremely primitive, it is just a Logical volume which is positioned inside its mother Logical Volume. It consists of the name of the Logical Volume to be positioned, together with the transformation matrix from the local reference system of the mother Logical Volume to the local reference system of the daughter Logical Volume. PVolume is not identifiable and implements the IPVolume interface.
The important point here is that a given logical volume can have several times the same logical volume as a child, using several different physical volumes. This is the way volumes can be replicated without replicating the objects in memory.
More detail, especially concerning the implementation can be found in "Volumes", by I. Belyaev at http://cern.ch/lhcb-comp/Frameworks/DetDesc/Documents/volumes.pdf
8.4.2.3 Solids and surfaces
All solids implement the ISolid interface. Currently, seven types of "primitive" solid are implemented: Boxes, Simple Trapezoids, Tube segments, Conical tube segments, Polyconical tube segments, Sphere segments and General trapezoids. Here is a very quick overview of each of them:
· box is obvious.
· trd is a simple trapezoid defined by two rectangles, orthogonal to the Z axis and centered on it, and a Z size.
· trap is a more generic trapezoid defined by a direction (theta, phi), that replaces the previous Z axis, a length along this axis and two faces orthogonal to the axis, which are kinds of trapezes. Actually, the faces are defined by two segments parallel to what replaces the X axis, the distance between them and the angle between the orthogonal line to these segments and the line joining the middle of both segments.
· tubs is a part of a section of tube. The tube is centered on the Z axis and defined by its inner and outer radius. It is then cut to keep a section of a given length centered at the origin. Last, only the part between phi and phi + deltaPhi is kept.
· cons is a part of a section of cone. The cone is defined along the Z axis and its section is defined by the inner and outer radius at each extremity plus the height of the section. Last, only the part between phi and phi + deltaPhi is kept.
· polycone is a part of several cone sections. The cone is defined along Z and the sections are defined by a number of triplets giving for several location in z the inner and outer radiuses of the polycone in these places. At last, only the part between phi phi deltaPhi is kept.
· sphere is a kind of sphere part but with a thickness. The thick sphere is defined by an inner and an outer radius. Then only a portion of the whole sphere is kept, defined by its theta and phi angles.
These solids were chosen from the most frequently used shapes in the GEANT3 and Geant4 toolkits - more shapes can be implemented if necessary. In addition, Boolean Solids have been defined, which allow Subtraction, Union and Intersection operations on solids, to build complex shapes. Details concerning the implementation are available in "Solids" by I. Belayaev at http://cern.ch/lhcb-comp/Frameworks/DetDesc/Documents/Solids.pdf
The class Surface handles surfaces. Details are available in "Optical properties & Surfaces" available at http://cern.ch/lhcb-comp/Frameworks/DetDesc/Documents/Optical.pdf
8.4.3 Materials
The description of materials is actually the description of their chemical composition plus some parameters.
The parameters are the same for all kinds of materials, they are radiation length, density, lambda, temperature, pressure and state. On top of that, tabulated properties can be added.
Concerning the chemical composition, three kinds of materials are distinguished, each of them corresponding to a given class. Here is a short description of each :
· Isotope : this is the definition of a given isotope of a given atom. It has an atomic mass, an atomic number and a number of nucleons.
· Element : this is a real life element, that is in general a mixture of several isotopes with given proportions. It has an effective atomic mass, an effective atomic number and an effective number of nucleons.
· Mixtures : this defines a mixture of several elements or even several other mixtures with given proportions.
8.4.4 Alignment, Calibration, Readout, SlowControl, FastControl
The description of these time varying detector "conditions", as previously stated, has so far only been implemented in a very simple way. For each of these five categories, the corresponding data for a detector element is foreseen to be encapsulated in one Condition object of the given type, containing only the following:
· a set of user defined parameters and parameter vectors, each one defined by a name, a comment, a type and a value (just like those for a detector element).
For all five categories of conditions, it is important to distinguish between the actual measured data and all other quantities which can be derived as a function of it: while the first kind of data must be stored in the persistent DDDB and retrieved by the framework from its persistent storage every time it becomes invalid, the second type of data should not, in general, be stored in the persistent DDDB. For instance, if the gain of a detector was a function of its temperature, only the coefficients of that functional dependence and the temperature of the detector should be read from the persistent storage, while its actual gain should be computed within the framework at processing time.
Similarly to class DetectorElement, it is foreseen that users may define their own types of Condition objects. This is however not recommended unless strictly necessary as, in general, an arbitrary list of parameters and parameter vectors should be sufficient for most uses. Specific questions concerning condition data should be answered by the interfaces like IAlignment and not by the Conditions themselves: it is then better to identify specific methods to extend these interfaces, rather than extend the Condition class.
8.5 Persistent representation based on XML files
The Gaudi detector description is based on text files whose structure is described in XML (eXtendable Markup Language). XML files are understandable by humans as well as computers. Data in XML are self-descriptive so that by looking at the XML data one can easily guess what the data mean. An advantage of XML is that there exists plenty of software which can be used for processing and manipulating data, as it is an industry standard.
In the future we expect to replace the XML files by an object persistency service, based on a database. However, the data may continue to be described in XML from the user point of view. These issues ar described in more detail in Section 8.6.
This part first gives a quick introduction to the XML langage and to the document type definitions (DTDs). The DTD used in the particular case of the LHCb detector description is deacribed. Then, the conversion from the persistent to the transient representation is presented as well as its specialization to address particular user cases. Finally, we give some ideas and references concerning the numerical expression parser used during the conversion process and the XMLEditor tool that could be used to edit the persistent representation.
8.5.1 Brief introduction to XML
8.5.1.1 XML Basics
XML is one example of what is called markup languages. Another well-know example of it is HTML. The specificity of this class of langages is the usage of "tags" to structure the code. A tag is actually a marker (or a pair of them, one for opening and one for closing) that delimits a given part of the code. In the case of both XML and HTML, they look like <...> for opening tags or </...> for closing tags.
The very basic and mandatory rule of markup langages is that all tags must nest properly. Proper nesting means that each opening tag has its corresponding closing tag and that this one must appear before the parent's tag closing tag, as shown in Listing 8.6.
Listing 8.6 Properly nesting in markup languages
<ProperNesting> <Something>In</Something> </ProperNesting>
<WRONGNESTING> <BADTHING>huhu </WRONGNESTING> </BADTHING>
The specificity of XML among other markup languages is that it is extendible. This means that a user can define his own tags. For example, Listing 8.7 shows the XML file which describes an e-mail (Forget the first two lines and the TimeStamp item, we will describe them later).
At first sight this markup language looks like screwed-up HTML. This is because HTML is only a subset of XML (with a fixed set of tags). Unlike HTML, you cannot guess from the example above how to present the data described there nor how to visualize them. What is clear however is the meaning of the data items encoded in XML. Thus one can easily recognize the data items and guess what they mean. On the other hand it is relatively easy to instruct a computer program what to do with the given data item according to the XML markup elements it is encapsulated in. Let us analyse the example shown in Listing 8.7.
8.5.1.2 XML components
XML declaration
must be at the beginning of each XML document. It is the first line in the example. It says that this file is an XML file conforming to the XML standard version 1.0 and is encoded in UTF-8 encoding. The encoding is very important because XML has been designed to describe data using the Unicode standard for text encoding. This means that all XML documents are treated as 16-bit Unicode characters instead of usual ASCII. So, even if you write your XML files using 7- or 8-bit ASCII, all the XML applications will work with it as with 16-bit Unicode XML data. The encoding information is important, for example when an XML document is transferred over the Internet to some other country where a different encoding is used. If the receiving application can guess the XML encoding from the received file, it can apply transcoding methods to convert the file into proper local encoding, thus preserving readability of the data.
XML comments
look like comments in SGML or HTML. They start with <!-- and end with -->. Comments in XML cannot be nested. This means you cannot open comments inside comments, as you can open a tag inside another tag.
XML elements
are the tags. In the example we had the following XML elements: Email, TimeStamp, Sender, Recipient, Subject, Body, Signature. The very basic and mandatory rule of XML is that all XML element tags must nest properly (this is a markup lanagage) and that there must be only one root XML element at the top level of each XML document, which contains all the others. An XML document that follows these rules is called well-formed. An example is the XML document in Listing 8.7.
XML elements are actually a bit more complex than regular tags. They can contain what is called attributes. These are pairs of the form name=value that are embedded inside the opening part of the tag. This is the case in the TimeStamp tag in Listing 8.7. Two attributes are defined there : date and time. Attributes usually describe the properties of the given element. The value of an attribute is a string and it has to be enclosed inside quotes (single or double, it doesn't matter). In the content of a given tag, raw text can appear among nested XML elements. This is called text data.
8.5.1.3 Document type definitions (DTDs)
The XML documents described up to now are well formed since they follow the syntax rules of XML. This is a first step but one may want to add some grammar inside an XML document so that you are not allowed to use any XML element you could imagine in any place.
This is possible by writing a document type definition (DTD). It can be integrated inside the XML file itself (internal DTD) or can be given in a separated file (external DTD). The external case is the most used since the external file can be reused by many XML files and thus ensure consistency between them.
The DTDs are actually written using a markup langage too. The main features of a DTD are:
· the definition of an XML element (ELEMENT tag of the DTD) : this specifies the name of the XML element and its possible children
· the definition of the attributes of an XML element (ATTLIST tag of the DTD): this specifies the attributes of a given XML element, as well as their usage (required, default value, ...)
We will not describe here further the syntax of the DTD file since it would be too long but it is pretty obvious to understand.
Listing 8.8 gives an example of the definition and usage of an external DTD for an XML file. Another example is the HTML langage. It can be seen (with small exceptions) as the definition of a given DTD, that is used to describe a hypertext document and the way it should be displayed.
Now that the XML file has a grammar, it is called valid if it fulfils the grammar requirements. Otherwise, it is not valid, even if well-formed. The process by which the grammar of a given XML file is checked is called "validation process".
8.5.2 DTD of the LHCb detector description
In the case of the LHCb detector description, several DTDs have been defined in order to describe the structure, geometry and materials of the detector. These are detailed in a dedicated document : "The LHCb Detector Description DTD", by Sebastien Ponce, available at http://cern.ch/lhcb-comp/Frameworks/DetDesc/Documents/lhcbdtd.pdf. Thus, we will only give here a very short presentation of it.
You will find in the next few sections UML schemas of the different DTDs. For those who don't know this notation, here are the basics:
· every entity here is an XML element, with all the possible attributes enumerated
· following the arrows getting out of an element, you can know which elements could be children of it.
8.5.2.1 Some prerequisites
Some of the elements of the LHCb DTDs are defined in each of the three DTDs. Thus, we describe them here.
Expressions
Every numerical value required by an attribute or an element in any of the DTDs of LHCb is an expression. This means that the value will be evaluated by the numerical expressions parser (see Section 8.5.5)
Thus, most of the current units and constants are already known. You can safely use degree, rad or pi for angles for instance. On top of that, many mathematical functions are also known, such as sin, or exp but also arctan and many others.
Parameters
A special tag called parameter is defined in all DTDs of LHCb. This element allows the user to define his own parameters that can be then reused in any expression or value in the rest of the XML code. It has a name, a type, a value and a comment.
The parameter element is actually a kind of macro since at parsing time it will be replaced by its value wherever it appears.
References
In the description of the LHCb DTD, you will see a lot of nodes with names finishing by "ref". Each time there is a corresponding node without the "ref". The "ref" nodes are actually references on the "without ref" ones. All of them have almost the same usage and syntax. The common things they have are attributes for class ID and hyperlink reference. The hyperlink is in general specified using the format:
The protocol and hostname parts can be omitted if the file resides on the local host. It is possible to write a hyperlink without the full path name in case one needs to refer to an XML object residing inside another file. In this case the relative path will be appended to the location of the currently parsed XML file.
For example having the current file location /full/path/to/current.xml and inside this file a hyperlink as href="next/file.xml#NextOID" the hyperlink will be resolved as /full/path/to/next/file.xml#NextOID.
If the hyperlink has the form #ObjectID this means that the referred object is located in the current file.
Note that relative paths are strongly encouraged for every file except the top-most one, since the whole set of files may be copied to several different locations one day.
8.5.2.2 The structure DTD
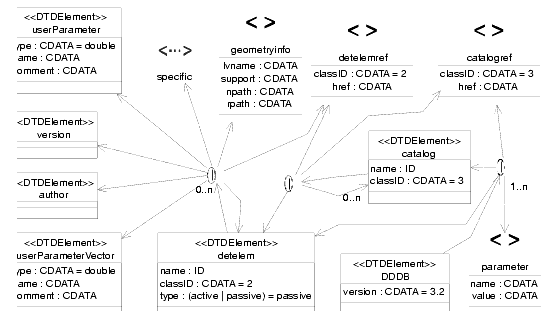
The schema of the DTD that should be used for every file describing the structure of the LHCb detector is shown in Figure 8.4. Presently, this DTD is also used for the files containing the description of all kinds of generic condition data such as alignment, although a simpler DTD would be enough.
Figure 8.4 The Structure DTD
Let's describe quickly some of the elements (the others are trivial) :
· DDDB : this is to fulfill the XML basic rule that each XML document must have only one root XML element This is the root element.
· catalog : this is simply a list of elements, with a given name. This is a way to classify detector elements.
· detelem : detector elements are the essential part of the structure of the detector description. They fully describe a given part of the detector by holding data on the geometry of this part as well as on the subparts constituting it.
· userParameter and userParameterVector: this allows the user to add a parameter or a vector of parameters for a given detector element. This is intended to be used for specific parameters appearing in the subdetector descriptions. Their usage is described deeper in another document : "Extending detector Elements and implications", by Sebastien Ponce, available at http://cern.ch/lhcb-comp/Frameworks/DetDesc/Documents/detElemExtension.pdf
· condition: a condition is simply a container of parameters and parameter vectors.
· geometryinfo: this tag describes the geometry of a given detector element.
· alignmentinfo, calibrationinfo, readoutinfo, slowcontrolinfo, fastcontrolinfo: these tags, when present, contain the name of the corresponding condition for a given detector element; if absent, no condition info of that type will be available.
· specific: this is the place where a user can extend the default detector description language and introduce new tags for his own needs. It is foreseen that the new XML elements be defined in a local DTD section of the XML data file or in a specific DTD file. Its usage is described deeper in "Extending detector Elements and implications", by Sebastien Ponce (See location above).
8.5.2.3 The geometry DTD
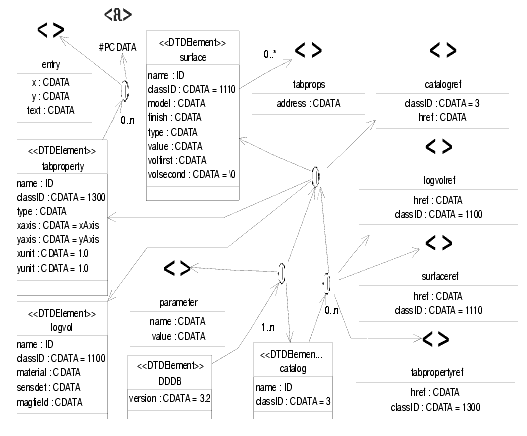
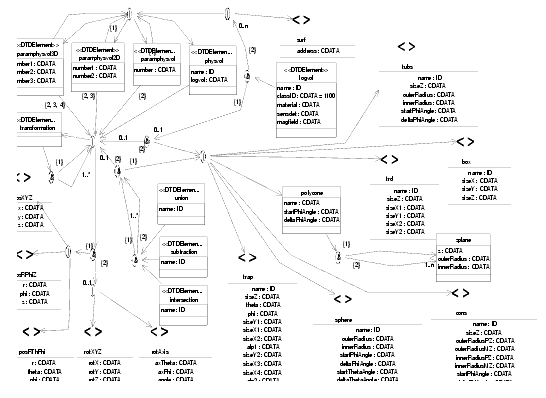
We schema of the DTD that should be used for every file describing the geometry of the LHCb detector is shown in Figure 8.5
.and Figure 8.6
Figure 8.5 Geomety DTD (part 1)
.
Figure 8.6 Geometry DTD (part 2)
Let's describe quickly some of the elements (the others are trivial or explained in the specialized documentation, see Section 8.5.2) :
· DDDB : this is to fulfill the XML basic rule that each XML document must have only one root XML element This is the root element.
· catalog : this is simply a list of elements, with a given name. This is a way to classify the logical volumes.
· tabproperty : this defines a tabulated property. This is used to describe optical properties of materials and surfaces. See "Optical properties & Surfaces" available at http://cern.ch/lhcb-comp/Frameworks/DetDesc/Documents/Optical.pdf.
· surface : this defines a surface, see Section 8.4.2.3.
· transformation : this defines a new transformation, by composition of several others
· logvol, physvol : these are the mapping of the C++ classes described in Section 8.4.2.2
· paramphysvol, paramphysvol2D, paramphysvol3D : these are ways to define many physical volumes in one shot, by replicating a given volume and applying a given transformation between each replica.
· posXYZ , posRPhiZ , posRThPhi : these are 3 ways of defining a translation : cartesian, cylindrical and spherical coordinate systems.
· rotXYZ , rotAxis : these are two ways of defining a rotation. Either along X, Y or Z axis, or along a user-defined axis.
· box, trd, trap, cons, polycone, tub, sphere : these are all kinds of solids. They are described in Section 8.4.2.3 on page 71. Note that polycone uses a subelement called zplane to define the different sections of the polycone.
· union, subtraction, intersection : these are boolean operations on solids.
8.5.2.4 The material DTD
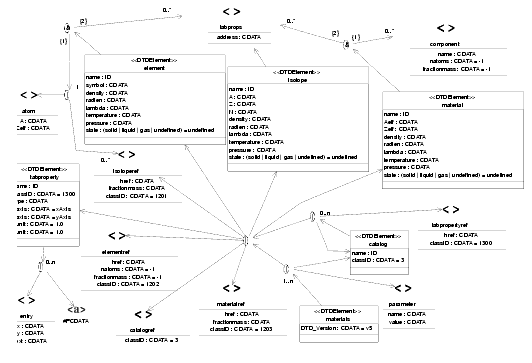
We the schema of the DTD that should be used for every file describing materials of the LHCb detector is shown in Figure 8.7
.
Figure 8.7 Material DTD
Let's describe quickly some of the elements (the others are trivial) :
· materials : this is to fulfill the XML basic rule that each XML document must have only the one root XML element This is the root element.
· catalog : this is simply a list of elements, with a given name. This is a way to classify materials.
· tabproperty : this defines a tabulated property. This is used to describe optical properties of materials and surfaces. See "Optical properties & Surfaces" available at http://cern.ch/lhcb-comp/Frameworks/DetDesc/Documents/Optical.pdf.
· isotope, element, material : this maps to the three classes Isotope, Element and Mixture described in Section 8.4.3.
· atom : this is used to define an element when it is not a mixture of isotopes.
· component : this is used to define mixtures. It associates a material and a proportion.
8.5.3 Conversion to transient representation
We describe here the conversion of data from the persistent to the transient world. This matter is actually the main topic of Chapter 13. Please refer to it for an explanation of how the conversion process works and is implemented into Gaudi. Here we give additional information on the special case of detector description data.
8.5.3.1 Overview
The main aim of the conversion process is to populate the transient store with C++ objects, using XML files. If you look at the description of the C++ objects in Section 8.3 and at the description of the XML files in Section 8.5.2, you will notice that there is almost a one to one mapping between the two, where XML elements become objects and XML attributes become members of these objects.
Thus, the conversion service (called XmlCnvSvc in our case) uses more or less one converter per XML element, or per kind of C++ object stored in the transient store. Here is the list of existing converters and the list of objects they are creating :
· XmlTabulatedPropertyCnv : deals with tabulated properties and creates TabulatedProperty objects.
· XmlSurfaceCnv : deals with surfaces and creates Surface objects.
· XmlMixtureCnv : deals with mixtures and creates Mixture objects.
· XmlLVolumeCnv : deals with logical volumes and creates LVolume objects. This is also the place where all the geometry is parsed and stored, including physical volumes, solids (simple and booleans), transformations and parametrized physical volumes. These last ones do not exist in the C++ world since they are expanded in a set of regular physical volumes.
· XmlIsotopeCnv : deals with isotopes and creates Isotope objects.
· XmlElementCnv : deals with elements and creates Element objects.
· XmlBaseDetElemCnv and XmlUserDetElemCnv: deal with detector elements and create DetectorElement objects.
· XmlBaseConditionCnv and XmlUserConditionCnv: deal with condition data and create Condition objects.
· XmlCatalogCnv : deals with catalogs and creates DataObject objects containing a list of references on other objects in the store.
8.5.3.2 XmlCnvSvc
The XmlCnvSvc is the service responsible for converting XML code into C++ objects. It implements the IXmlSvc interface and essentially provides two sets of methods:
· parser related methods : parse, clearCache and allowGenericCnv which respectively parses an XML file, clears the cache of parsed files and says whether user defined detector elements are converted using dedicated convertors or the generic converter. This last method is related to the job option property AllowGenericConversion.
· expression evaluator related methods : eval, addParameter, removeParameter which respectively computes the value of a given expression, adds a new parameter and remove a given parameter. Parameters can be used in any expression, as soon as they are defined. For more details, the expression evaluator is presented in Section 8.5.5.
8.5.3.3 XmlParserSvc
The XmlParserSvc is actually used by the XmlCnvSvc for parsing XML files. We will not describe it in detail here but just give some usefull hints.
This service is not only responsible for parsing XML files but also for implementing a cache on parsed files. This cache is very useful due to the behaviour of the transient store.
As a matter of fact, the transient store calls the XmlCnvSvc and thus, indirectly, the XmlParserSvc, every time an object is missing. When this occurs, an XML file is parsed and the object is created and put into the store. But all the objects contained in the XML file are not created and put into the store, only the ones needed. Thus, if the next missing object is defined in the same XML file, this one will be read again and parsed again.
That's where the cache is very useful: it avoids opening and parsing the same file again and again. A recent example showed that the cache could speed up the parsing with a factor 180 under certain conditions (1300 objects in the same file, read one by one).The important point is that this cache can be configured in order to be efficient for every special case. The two configuration parameters are :
· the maximum number of cached files. This is given by the MaxDocNbInCache property in the job options file. The default value is 10.
· the behavior of the cache. This is given by the CacheBehavior property in the job options file. The default is 2. The meaning of this parameter is a bit complicated. It is explained below.
8.5.3.3.1 CacheBehavior usage
· set CacheBehavior to 0 to have a FIFO (First in, first out) behavior
· put it to more to keep files that are reused. In this second case, the value of the parameter gives you the frequency of usage a given file should have to stay in the cache. Eg, for the default value, a file reused once every two file usages will stay forever in the cache.
The complete explanation is the following :
· for each item in the cache, its birthDate and its utility are stored. The birthDate is the age of the cache at the time the item was added to it and the age grows by 1 each time a file is requested, be it in the cache or not. The utility is the number of times the cached item is accessed, once it is in the cache.
· when the cache is full, the following value is computed for every item: birthDate + CacheBehavior * utility. The item with the smallest score is removed from the cache.
So, if CacheBehavior = 0, the item with the smallest birthDate is removed, which means the oldest. So it is a FIFO. If not, the thing is a bit more tricky but imagine that you request the same file every CacheBehavior requested files. The utility of this file will be (cacheAge - birthDate) / CacheBehavior and thus, its score will be cacheDate, which is the best possible score for a new arriving file. So this file will be kept. Files that are less often used will have a score further and further from the one of the last arrived file and will eventually be deleted. Files more often accessed have better scores and will be kept.
8.5.3.4 Converters implementation overview
We give here a quick overview of the converters implementation to give an idea of what to do if you want to extend them. This process of extension will be anyway detailed for the case of detector elements in Section 8.5.4.
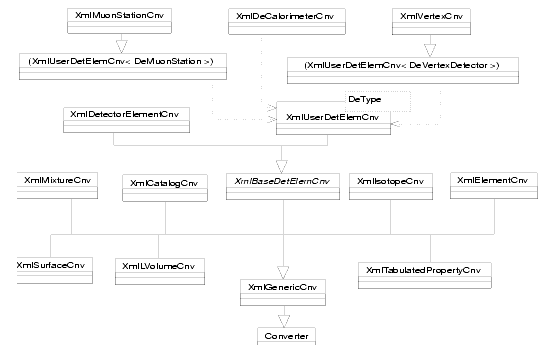
Figure 8.8 C++ class hierarchy for converters
Figure 8.8 gives an overview of the tree of classes defining the whole set of converters. As explained in Chapter 13, every converter inherits from the class Converter and implements the methods initialize, finalize, createObj, updateObj, createRep and updateRep. In the case of the XML converters, the method createObj (the only currently implemented one among the create* and update* methods) is pretty much always the same: retrieve the right XML file, parse it, check the version, find the element to retrieve, create the corresponding C++ object, fill it with its children if needed, make some computation on it and store it.
The only three points where things are converter specific are thus the creation of the object, its filling and the computation made on it. The rest of the code is common and it was put into XmlGenericCnv. Only three virtual methods have to overriden to implement a new converter from the generic one : i_createObj, i_fillObj and i_processObj.
In the case of detector elements, it is a bit more tricky since we want users to be able to extend easily the default converter to add their own stuff. This is done by putting all the default code inside XmlBaseDetElemCnv and defining a new method, called i_fillSpecificObj, that has to be implemented by the user in case he adds some stuff. The default converter XmlDetectorElementCnv only gives an empty implementation for this method.
See 8.5.4 for more details.
8.5.4 Customizing a detector element
This topic is developed in a dedicated documentation : "Extending detector elements and implications", by Sebastien Ponce, available at http://cern.ch/lhcb-comp/Frameworks/DetDesc/Documents/detElemExtension.pdf. Thus, we will only give here a quick overview of the possibilities without any explanation on how to practically do the job.
There are three ways of customizing a detector element, from the simplest but less flexible one to the most complicated, but most flexible one :
· the first one only allows the user to add parameters (or vectors of parameters) to the default DetectorElement object in C++.
· the second one allows the user to define a new C++ object, inheriting from the default DetectorElement. He can thus do some computation inside the object, using the parameters defined in the first case.
· the last method allows the user to redefine the DTD used in the XML files and to manage structured data instead of just parameters.
8.5.4.1 UserParameters
This is the simplest way to add specific information to a detector element without having to write too much code. It is based on the userParameter and userParameterVector tags defined in the structure DTD of the LHCb detector description files.
The userParameter and userParameterVector tags are children of the detelem tag. They can appear anywhere in the definition of a detector element. Listing 8.9 shows some examples of the usage of user parameters:
Once user parameters are defined in XML, they are converted by the regular converter for detector elements and are then reachable in the C++ code using the following methods of the class DetectorElement : userParameters, userParameterVectors, userParameter, userParameterAsString, userParameterAsInt, userParameterAsDouble, userParameterType, userParameterComment, userParameterVector, userParameterVectorAsString, userParameterVectorAsInt, userParameterVectorAsDouble, userParameterVectorType and userParameterVectorComment
The method name should be self-descriptive. For more details, go to the dedicated documentation.
8.5.4.2 Customizing the detector element
The preceeding section showed us how to define user parameters inside a regular detector element. We describe here how it is possible to define new C++ classes, inheriting from the original DetectorElement class. This has for consequence that the generic converter provided with Gaudi can no longer do the job, since it is not aware of the existence of this new class. Thus, we have to create a new converter, by customizing a bit the default one.
This is done by using the templated class XmlUserDetElemCnv<DeType> which allows the users to define his own converter for his own type of detector element. It actually inherits the behavior of the default converter and avoids the user to rewrite existing code. The only difference here is that it creates an object of type DeType instead of a regular DetectorElement.
The parameter class DeType has only few constraints: it must inherit from DetectorElement, it must have a default constructor with no parameters and it must have a new classID, which has to be unique in whole LHCb software. Appart from that, you have full freedom to use you own class and to add whatever methods or members you may want to the default DetectorElement.
In addition, one could override the methods of DetectorElement. This is not recommended at all except for the method initialize(). This one is a kind of hook for the user. It is called by the converter just after the creation of the object and before its first use. It allows the user to initialize some members using the values parsed from the XML, for example user parameters.
8.5.4.3 Extending the DTD
This last way of extending a detector element is the most flexible one. It allows to define new XML children tags for the detelem tag. This is actually the goal of the specific tag. It allows the user to extend the default DTD of the XML file where his detector element resides and to use the new tags to add structured data. These data will then be used by a user defined converter to build a detector element.
The extension of the DTD and the use of the specific tag are not explained here since they are straightforward for someone who knows XML. More details are available in the dedicated documentation.
Concerning the C++ part, the situation is pretty much the same as before: a new converter must be defined. This looks like the previous one except that it has one more method implemented (actually overridden from XmlUserDetElemCnv) :
StatusCode i_fillSpecificObj( DOM_Element childElement,
DeType* dataObj);This method uses the DOM interface, which is an interface to XML parsers. If you don't know it and thus don't know what a DOM_Element is, please refer to the dedicated documentation.
The principle of the i_fillSpecificObj method is pretty simple : it is called by the XML parser service everytime a tag is found directly inside a specific tag. The parameters are then the DOM_Element corresponding to the tag found and the C++ detector element object being built when this occured.
Thus, for the XML code in Listing 8.10 the method will be called twice, once for Al_plate_thickness and once for pad_dimensions. It will not be called for padX or padY.
This method is thus the place where the XML code can be browsed and data extracted to be put inside the detector element object.
8.5.5 Numerical expressions parser
The framework provides a simple evaluator of numerical expressions based on the CLHEP expression evaluator. It is available for Gaudi framework converters as well as for the user defined converters. The only difference is that in user defined converters the parser is not instantiated explicitly by the user but is accessed through the IXmlSvc interface instead.
The numerical expressions recognized by the parser can be composed of integers and floating point numbers assuming one of the formats:
Supported operations are: + - * / unary +|- exponent ^
Parenthesized expressions: 1.4 * (23.4-e12 / 1.8)
Operator precedence is: () unary +|- ^ *|/ +|-
In addition, the parser understands CLHEP units. The result is always evaluated to double value. The check for the presence of CLHEP units inside expressions is enabled by default. To suppress this behaviour the call of the eval() method must look like:
For further information about this expression parser, please go to the CLHEP documentation at http://wwwinfo.cern.ch/asd/lhc++/clhep/manual/UserGuide/index.html
8.5.6 XML Editor
The XML editor is a tool provided to edit the XML files of the detector description database without having to learn the XML syntax. It is provided as a separate Gaudi package and was written in Java. Documentation is available at http://cern.ch/lhcb-comp/Frameworks/DetDesc.
8.6 Persistent storage in a Conditions Database
While the current implementation of the Gaudi detector description, based on text files in the XML language, is perfectly adequate to describe detector data for which only one or at most a few versions exist (as in the case of the detector logical structure, geometry or materials), a file-based persistent storage is not adequate to describe detector data which is rapidly changing in time, such as slow control measurements of temperature and pressure. It is therefore foreseen that this data will be stored in a database, the so called Conditions Database (or CondDB). Once this storage system is fully functional, it could also be used to store the description of the structure and geometry of the detector, keeping track of its possible time variation due to the installation or removal of subdetector elements between different years.
8.6.1 Generalities on the Conditions Database
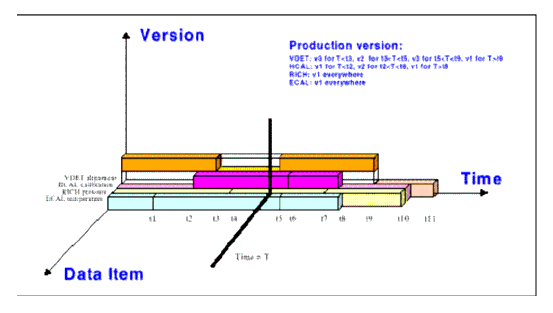
The main user requirements and abstract interfaces for the CondDB have beed described in the document "Conditions Database for LHCb: Interface Specification Proposal", by Pere Mato, available at http://cern.ch/lhcb-comp/Frameworks/DetCond/conddataspecs.pdf: only a quick overview of the system will be given here. In summary, each block of condition data stored in the CondDB, indipendently from its data content, has the following three characteristics, as shown in Figure 8.9:
· the name of the data type it refers to (such as "/SlowControl/Hcal");
· the time range during which it is valid, i.e. an interval of the form [since, till];
· a version number (such as the version of the alignment algorithm used).
Figure 8.9 The three axes for identifying uniquely each block of data stored in the conditions database.
The collection of all data blocks referring to the same data type, for any given validity time and version number, will be called a "condition folder" in the following, while a collection of condition folders will be referred to as a "condition folderset": in the example above, "/SlowControl" is the name of the folderset containing folder "SlowControl/Hcal". Instead of a version number, a "tag" name will most often be used to indicate a consistent set of condition data blocks of a given folder, such that at every given time only one such data block within the folder has the given tag. In addition to "local" tag names defined for a given folder, "global" tag names defined over a collection of many folders of the CondDB can also be used. As a consequence, a block of condition data can be retrieved from the CondDB by specifying three variables: a folder name, a validity time and a (local or global) tag name.
The actual data content of each condition block is required to consist of a byte stream, which may be taken to represent a string. This may be used, for instance, to store XML documents as strings in the CondDB, rather than as text files like in the present implementation of the LHCb DDDB. Eventually, other possibilities may be investigated, such as storing C++ objects serialized as byte streams, or storing a string containing an object identifier in an Objectivity database or a table identifier in an Oracle database.
8.6.2 Conditions Database prototype implementation and examples
In collaboration with LHCb and other experiments, a conditions database system with these characteristics has recently been developed by the CERN IT/DB group (see online documentation at http://wwwinfo.cern.ch/db/objectivity/docs/conditionsdb).The current implementation of this product is based on the Objectivity object database system, but another implementation based on the Oracle relational database is being developed by the same group. It has been decided that the production version of the LHCb conditions database will be based on the Oracle implementation of this package, a first prototype of which might be ready to be used by the next Gaudi software release. In the meantime, the package based on Objectivity has been used to prototype the relevant services of the Gaudi framework.
8.6.2.1 Relevant CMT packages
An example of an algorithm retrieving time-varying condition data from the CondDB exists in package DetCondExample v2r0. This uses a number of CMT packages, as shown below,
use DetCond v2r0 Det
use DetDesc v9* Det
In addition to the generic detector description code from DetDesc, the example makes use of package DetCond, containing the relevant conversion service for DataObjects stored in the CondDB, class ConditionsDBCnvSvc, described later on. Package DetCond, in turn, depends on package CONDDB which allows to use Objectivity and the corresponding implementation of the CondDB package from the IT/DB group.
Package DetCondExample does not use the production version of the DDDB from XmlDDDB, as it contains its own simplified private version of the DDDB. Two examples are actually contained in this package: one tests the retrieval of Condition objects, stored in XML files, through the specialised interfaces of a detector element such as IAlignment; another tests the retrieval of Condition objects, stored in XML strings in the Objectivity based CondDB, using the ConditionsDBCnvSvc. In this second example, a third job options file allows to populate an Objectivity conditions database using sample data.
While the first example works under both Linux and Windows, the second example only works under Linux, as Objectivity is currently not supported under Windows at CERN. The two examples test different branches of the same DDDB tree, showing that file-based and CondDB-based persistency systems can be used at the same time. The following will concentrate on the description of the CondDB example.
8.6.2.2 Condition objects in the Gaudi store and data blocks in the CondDB
While user algorithms are only meant to retrieve Condition objects by a request to the corresponding interface of a DetectorElement (for instance, the Hcal slow control Condition is accessible as hcal->slowControl()->condition(), as described in Listing 8.4), it is important to understand the underlying mechanism to retrieve them into the transient store from their persistent representation in the CondDB.
To start with, it is assumed in the following that all parameters and parameter vectors which refer to the same detector element and share the same time validity range should be grouped together into the same Condition object, and that one and only one such Condition should be stored in each data block in the CondDB. While more than one Condition could be stored in the same data block (just like two different elements can be stored in the same XML file), two such Conditions would be forced to share the same validity range, folder name and tag, and are best thought of as two different subsets of parameters of the same Condition. This one-to-one correspondence between the granularity of transient Condition objects and persistent data blocks in the CondDB can be relevant for time performance reasons.
In the design of the framework services for Condition data in the CondDB, it is further assumed that, for every condition folder in the CondDB, only one Condition object from that folder can be loaded in the Gaudi transient data store, i.e. that which is valid at the time of the current event, and for a given global tag specified by the user in the job options. This allows to set a one-to-one correspondence between a folder name, and a path name in the Gaudi store.
In summary, in response to a statement like hcal->slowControl()->condition(), the three variables necessary to retrieve a block of condition data from the CondDB, the folder name, the tag name and the validity time, are determined as follows.
· The validity time is a property of the DetectorDataSvc. While in the example it is set by an external "clock" using the IDetDataSvc special interface, eventually the DetectorDataSvc should read it from the current event data whenever it is interrupted by an Incident signalling the start of a new event.
· The default global tag is a property of the ConditionsDBCnvSvc, set in the job options
// Production version of detector conditions
ConditionsDBCnvSvc.condDBGlobalTag = "PRODUCTION";
· Last, the folder name of the requested data block in the CondDB is dictated by two distinct associations: that of the Hcal interface for slow control information to the path name in the transient store where its Condition must be loaded, and that of this path name to a folder name in the CondDB (which requires the use of a specially defined protocol "conddb:/folderset/folder#entryName"). In the example, both these associations are defined in file-based XML part of the DDDB, as follows.
It should also be mentioned that special users of the CondDB may need to use condition data in a different way: for instance, one may want to compare two versions of the alignment, accessing at the same time data blocks from the same folder and valid at the same time, but for different global tags. Whenever one needs to access two Condition objects corresponding to the same condition folder, but valid at different times, or differently tagged, this is still possible by direct access to the ConditionsDBCnvSvc through the methods of its special IConditionsDBCnvSvc interface. In other words, Condition objects may be created for arbitrary folder names, tag names and validity times, but they only exist in C++ memory while they are not loaded into the Gaudi data store.
8.6.2.3 Creation of Condition objects in the ConditionsDBCnvSvc
The conversion of condition data from their persistent storage as XML strings in the CondDB into transient C++ objects of class Condition in the Gaudi data store is more complex than a typical conversion process, such as that of detector elements stored in XML files. The difference is that two persistency mechanisms are used here, the storage of objects as XML strings and the storage of these strings in the CondDB. As a consequence, the conversion service responsible to retrieve Condition objects from the CondDB, the ConditionsDBCnvSvc, is a special type of conversion service. While it has no converters of its own, it is responsible to retrieve XML strings from the CondDB, then send them to another conversion service, the XmlCnvSvc described in Section 8.5.3.2, which in turn sends them for conversion to the appropriate converter (an XmlUserConditionCnv, in this case). After the creation of a Condition object, the XmlCnvSvc returns it to the ConditionsDBCnvSvc, which before returning control sets the appropriate validity range of the Condition, using the information retrieved from the CondDB.
While the example in the DetCondExample package stores and retrieves XML strings from the CondDB, the behaviour of the ConditionsDBCnvSvc does not assume that the data strings retrieved are written in XML. The "secondary" storage type for data blocks in the CondDB, which in this case is XML, is also discovered at runtime in the CondDB, by reading it off from the "description" of the corresponding CondDB folder, a single string which is meant to refer to all data blocks in the folder, independently of their validity ranges and version numbers.
8.6.2.4 Update of Condition objects
Eventually, it is foreseen that the DetectorDataSvc would automatically update all Condition objects loaded in the transient store it manages, whenever they become invalid. In the present implementation, this functionality is not yet provided, and Condition objects must be explicitly updated inside the algorithms before they are used, as in the following example. This will be modified by the time of the next release..
When requested to update a DataObject, the DetectorDataSvc does nothing if the requested objected does not implement IValidity or if it is still valid at the time of the current event. Otherwise, the request is propagated through the DetPersistencySvc to the appropriate conversion service, i.e. the ConditionsDBCnvSvc for data stored in the CondDB.
The ConditionsDBCnvSvc handles update requests for data objects in the following way. In principle, it should propagate an update request to the secondary conversion service, from where in turn it would be dispatched to the appropriate converter. However, this requires that the updateObject() method of the appropriate converter (XmlUserConditionCnv for a Condition object) is properly implemented, while currently this is not the case. Eventually, all converters of data that implements the IValidity interface (including DetectorElements, if these are to be stored in the CondDB) should implement this method: for Xml converters, this could be done by moving the parsing of Xml strings from the createObject() to the updateObject() method, calling the latter from inside the former. In the present implementation, update requests are handled by creating a new object of the given type, then copying its contents into the location referred to by the pointer to the old object. This "deep" copy of a Condition is actually not a complete deep copy, as the data members of the old DataObject which concern its location in the Gaudi store should not be changed. Rather than by an overloaded operator=, the update of the contents of the old Condition using selected contents of the new Condition is performed using the virtual void method Condition::update(Condition& obj). This method needs to be properly overloaded by all users desiring to write derived Conditions, to perform a deep copy of any additional data members.
1 Note that, by comparison with Figure 8.2, the leading "/dd/" has been omitted from the full path name "/dd/Structure/Velo/VStation01" of the detector element. Either form is accepted; the short form must never begin with a "/" character.
2 This operation can be time consuming!
3 This is equivalent to the absence of the 'MANY' flag in the GEANT3 toolkit.
4 Within the Geant4 toolkit there exist two approaches for solving the same problem: Read-Out-Geometry Tree and Navigator. Our approach is quite close to the combined usage of both.
|
Quadralay Corporation http://www.webworks.com Voice: (512) 719-3399 Fax: (512) 719-3606 sales@webworks.com |