| | |
GAUDI User Guide
| | |
GAUDI User Guide

In this chapter we walk through one of the example applications (
Histograms
) which are distributed with the framework. We look briefly at the different files and go over the steps needed to compile and execute the code. We also outline where various subjects are covered in more detail in the remainder of the document. Finally we cover briefly the other example applications which are distributed and say a few words on what each one is intended to demonstrate.
Traditionally, a "job" is the running of a program on a specified set of input data to produce a set of output data, usually in batch.
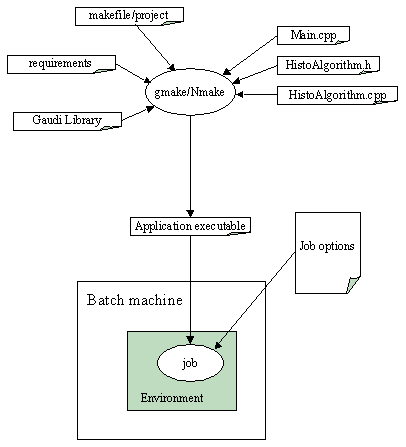
For the example applications supplied this is essentially a two step process. First the executable must be produced, and secondly the necessary environment variables must be set and the required job options specified, as illustrated in Figure 3
The example applications consist of a number of "source code" files which together allow you to generate an executable program. These are:
|
In order for the job to run as desired you must provide the correct configuration information for the executable. This is done via entries in the job options file.
An example main program is shown in Listing 1 on See The example main program. . It is constructed as follows:
The application framework makes use of a job options file (or possibly a database in future) for job configuration. The job options file of the Histograms example application is shown in Listing 2 on See The job options file for the Histograms example application. .
The format of an options file is discussed fully in Chapter 11 . Options may be set both for algorithms and services and the list of available options for standard components is given in Appendix Appendix B .
For the moment we look briefly at one of the options. The option TopAlg of the application manager is a list of algorithms that will be created and controlled directly by the application manager, the so-called top-level algorithms. The syntax is a list of the form:
ApplicationMgr.TopAlg = { "Type1/Name1","Type2/Name2" }; |
The line above instructs the application manager to make two top level algorithms. One of type Type1 called "Name1" and one of type Type2 called "Name2". In the case where the name of the algorithm is the same as the algorithm's type (i.e. class), only the class name is necessary. Thus, in the example in Listing 2 line 12 , an instance of the class "HistoAlgorithm" will be created with name "HistoAlgorithm"
The subject of specialising the Algorithm base class to do something useful will be covered in detail in chapter 5 . Here we will limit ourselves to looking at the class HistoAlgorithm in the example just to get an idea of the basics. For the full listing of this class, refer to the software distribution. Here we look only at those parts of the code which do something interesting and leave the technicalities for later.
The HistoAlgorithm class definition is shown in Listing 3 .
The implementation file contains the actual code for the constructor and for the methods: initialize(), execute() and finalize(). It also contains two lines of code for the HistoAlgorithm factory, which we will discuss in section 5.3.1
The application manager invokes the sysInitialize() method of the algorithm base class which, in turn, invokes the initialize() method of the base class, the setProperties() method, and finally the initialize() method of the concrete algorithm class. As a consequence all of an algorithm's properties will have been set before its initialize() method is invoked, and all of the standard services such as the message service are available. This is discussed in more detail in chapter 5 .
Looking at the code in the example we see that depending on the value of the histogram flag the HistoAlgorithm class may also create two histograms at initialisation and declare them to the histogram data service (see Chapter 9 for details on the use of histograms in Gaudi):
In order to use the objects within the container an iterator is defined (line 20 ) and the second histogram is filled with the energy of the tracks (line 24 ).
The details of the event data store and how data is accessed are discussed in Chapter 6 .
MsgStream log( messageService(), name() ); log << MSG::INFO << "finalize" << endreq; |
The first line creates a local MsgStream object, which uses the Algorithm's standard message service via the messageService() accessor, and the algorithm's name via the name() accessor. The use of these is discussed in more detail in Chapter 11 .
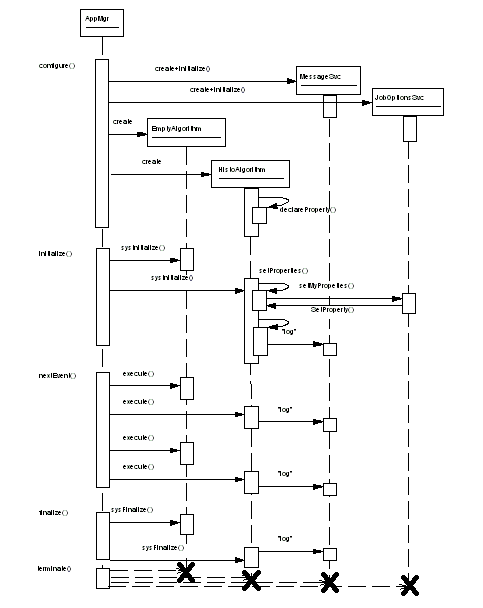
From the main program and the makefile or project file we can make an executable. This executable together with the file of job options form a job which may be submitted for batch or run interactively. Figure 4 shows a trace of an example program execution. The diagram is not intended to be complete, merely to illustrate a few of the points mentioned earlier in the chapter.
|
A number of examples is included in the current release of the framework. The intention is that each example exercises and shows to an end-user how to make use of some part of the functionality of the framework. The following table shows the list of available examples.
|
Example Name
|
Target Functionality
|
|---|---|
|
Actually not a complete example: contains main program used by many examples (DDexample, DumpEvent, Histograms, ParticleProperties) and system specific Job Options include files common to all examples (reproduced in Listings 29 and 30 on See The Standard Include Job Option File for NT Systems ) |
|
|
Making available existing Sicb magnetic field and geometry data to Gaudi algorithms. Example of nested algorithms |
|
|
Basic functionality of the framework to execute a simple algorithm, access event data and fill histograms. |
|
|
Example of use of OpenScientist with Gaudi (works only on Unix at CERN) |
|
|
Access the Particle Properties service to retrieve Particle Properties |
|
|
Two examples, reading and writing persistent data with ROOT RIO |
|
|
A realistic example of using the framework for a physics analysis, including access to Monte Carlo data, creation of reconstructed data and filling an n-tuple |