| | |
GAUDI User Guide
| | |
GAUDI User Guide

Services
are generally sizeable components that are setup and initialized once at the beginning of the job by the framework and used by many algorithms as often as they are needed. It is not desirable in general to require more than one instance of each service. Services cannot have a "state" because there are many potential users of them so it would not be possible to guarantee that the state is preserved in between calls.
In this chapter we give describe how services are created and accessed, and then give an overview of the various services, other than the data access services, which are available for use within the Gaudi framework. The Job Options service, the Message service, the Particle Properties service, the Chrono & Stat service, the Auditor service, the Random Numbers service and the Incident service are available in this release. The Tools service is described in Chapter 12.
We also describe how to implement new services for use within the Gaudi environment. We look at how to code up a service, what facilities the Service base class provides and how a service is managed by the application manager.
The Application manager creates a certain number of services by default. These are the default data access services (EventDataSvc, DetectorDataSvc, HistogramDataSvc, NTupleSvc), the default data persistency services (EventPersistencySvc, DetectorPersistencySvc, HistogramPersistencySvc) and the framework services described in this chapter and in Chapter 12 (JobOptionsSvc, MessageSvc, ParticlePropertySvc, ChronoStatSvc, AuditorSvc, RndmGenSvc, IncidentSvc, ToolSvc).
Additional services can be requested via the jobOptions file, using the property ApplicationMgr.ExtSvc. In the example below this option is used to create a specific type of event selector and the corresponding conversion service.:
ApplicationMgr.ExtSvc = { "SicbEventCnvSvc", "EventSelector"}; |
Once created, services must be accessed via their interface. The Algorithm base class provides a number of accessor methods for the standard framework services, listed on lines 25 to 35 of Listing 7 on See The definition of the Algorithm base class.. Other services can be located using the templated service function. In the example below we use this function to return the IParticlePropertySvc interface of the Particle Properties Service:
In components other than Algorithms, which do not provide the
service
function, you can locate a service using the
serviceLocator
function:
The Job Options Service is a mechanism which allows to configure an application at run time, without the need to recompile or relink. The options, or properties, are set via a job options file, which is read in when the Job Options Service is initialised by the Application Manager. In what follows we describe the format of the job options file, including some examples.
In general a concrete Algorithm, Tool or Service will have several data members which are used to control the execution of the service or algorithm. These data members can be of a basic data type (int, float, etc.) or class (Property) that encapsulates some common behaviour and higher level of functionality.
Simple properties are a set of classes that act as properties directly in their associated Algorithm, Tool or Service, replacing the corresponding basic data type instance. The primary motivation for this is to allow optional bounds checking to be applied, and to ensure that the Algorithm, Tool or Service itself doesn't violate those bounds. Available SimpleProperties are:
and the equivalent vector classes
The use of these classes is illustrated by the
EventCounter
class.
1. A default value may be specified when the property is declared.
2. Optional upper and lower bounds may be set (see later).
3. The value of the property is accessible directly using the property itself.
In the Algorithm constructor, when calling
declareProperty
, you can optionally set the bounds using any of:
setBounds( const T& lower, const T& upper ); setLower ( const T& lower ); setUpper ( const T& upper );
There are similar selectors and modifiers to determine whether a bound has been set etc., or to clear a bound.
bool hasLower( ) bool hasUpper( ) T lower( ) T upper( ) void clearBounds( ) void clearLower( ) void clearUpper( )
You can set the value using the "=" operator or the set functions
bool set( const T& value ) bool setValue( const T& value )
The function value indicates whether the new value was within any bounds and was therefore successfully updated. In order to access the value of the property, use:
m_property.value( );
In addition there's a cast operator, so you can also use
m_property
directly instead of
m_property.value()
.
CommandProperty
is a subclass of
StringProperty
that has a handler that is called whenever the value of the property is changed. Currently that can happen only during the job initialization so it is not terribly useful. Alternatively, an Algorithm could set the property of one of its sub-algorithms. However, it is envisaged that Gaudi will be extended with a scripting language such that properties can be modified during the course of execution.
The relevant portion of the interface to
CommandProperty
is:
class CommandProperty : public StringProperty { public: [...] virtual void handler( const std::string& value ) = 0; [...] };
Thus subclasses should override the
handler()
member function, which will be called whenever the property value changes. A future development is expected to be a ParsableProperty (or something similar) that would offer support for parsing the string.
The job options file has a well-defined syntax (similar to a simplified C++-Syntax) without datatypes. The data types are recognised by the "Job Options Compiler", which interprets the job options file according to the syntax (described in Appendix Appendix C together with possible compiler error codes).
The job options file is an ASCII-File, composed logically of a series of statements. The end of a statement is signaled by a semicolon ";" - as in C++.
Comments are the same as in C++, with '//' until the end of the line, or between '/*' and '*/'.
There are four constructs which can be used in a job options file:
An assignment statement assigns a certain value (or a vector of values) to a property of an object or identifier. An assignment statement has the following structure:
<Object / Identifier> . < Propertyname > = < value >; |
The first token (Object / Identifier) specifies the name of the object whose property is to be set. This must be followed by a dot ('.')
The next token (Propertyname) is the name of the option to be set, as declared in the declareProperty() method of the IProperty interface. This must be followed by an assign symbol ('=').
The final token (value) is the value to be assigned to the property. It can be a vector of values, in which case the values are enclosed in array brackets ('{`,'}`), and separated by commas (,). The token must be terminated by a semicolon (';').
The type of the value(s) must match that of the variable whose value is to be set, as declared in declareProperty(). The following types are recognised:
Please note that it is not necessary any more to define in the job options file the type for the value which is used. The job options compiler will recognize by itself the type of the value and will handle this type correctly.
Because of the possibility of including other job option files (see below), it is sometimes necessary to extend a vector of values already defined in the other job option file. This functionality is provided be the append statement.
An append statement has the following syntax:
<Object / Identifier> . < Propertyname > += < value >; |
The only difference from the assignment statement is that the append statement requires the '+=' symbol instead of the `=' symbol to separate the Propertyname and value tokens.
The value must be an array of one or more values
The job options compiler itself tests if the object or identifier already exists (i.e. has already been defined in an included file) and the type of the existing property. If the type is compatible and the object exists the compiler appends the value to the existing property. If the property does not exists then the append operation "+=" behaves as assignment operation "=".
It is possible to include other job option files in order to use pre-defined options for certain objects. This is done using the #include directive:
#include "filename.ext" |
The "filename.ext" can also contain the path where this file is located. The include directive can be placed anywhere in the job option file, but it is strongly recommended to place it at the very top of the file (as in C++).
It is possible to use environment variables in the #include statement, either standalone or as part of a string. Both Unix style ("$environmentvariable") and Windows style ("%environmentvariable%") are understood (on both platforms!)
As mentioned above, you can append values to vectors defined in an included job option file. The interpreter creates these vectors at the moment he interprets the included file, so you can only append elements defined in a file included before the append-statement!
As in C/C++, an included job option file can include other job option files. The compiler checks itself whether the include file is already included or not, so there is no need for #ifndef statements as in C or C++ to check for multiple including.
Sometimes it is necessary to over-ride a value defined previously (maybe in an include file). This is done by using an assign statement with the same object and propertyname. The last value assigned is the valid value!
The possibility exists to execute statements only according to the used platform. Statements within platform dependent clauses are only executed if they are asserted to the current used platform.:
|
(Platform-Dependent Statement) |
Only the variable WIN32 is defined! An #ifdef WIN32 will check if the used platform is a Windows platform. If so, it will execute the statements until an #endif or an optional #else. On non-Windows platforms it will execute the code within #else and #endif. Alternatively one directly can check for a non-Windows platform by using the #ifndef WIN32 clause.
We have already seen an example of a job options file in Listing 3 on See The job options file for the Histograms example application.. The use of the
#include
statement is demonstrated on line 6: the logical name
$STDOPTS
is defined in the
GaudiConf
package, which contains a number of standard job options include files that can be used by applications. Do not forget to
use GaudiConf v*
in your application to set up the necessary logical names.
One of the components directly visible to an algorithm object is the message service. The purpose of this service is to provide facilities for the logging of information, warnings, errors etc. The advantage of introducing such a component, as opposed to using the standard std::cout and std::cerr streams available in C++ is that we have more control over what is printed and where it is printed. These considerations are particularly important in an online environment.
The Message Service is configurable via the job options file to only output messages if their "activation level" is equal to or above a given "output level". The output level can be configured with a global default for the whole application:
|
// Set output level threshold (2=DEBUG, 3=INFO, 4=WARNING, 5=ERROR, 6=FATAL) |
and/or locally for a given client object (e.g. myAlgorithm):
Any object wishing to print some output should (must) use the message service. A pointer to the IMessageSvc interface of the message service is available to an algorithm via the accessor method msgSvc(), see section 5.2. It is of course possible to use this interface directly, but a utility class called MsgStream is provided which should be used instead.
The
MsgStream
class is responsible for constructing a Message object which it then passes onto the message service. Where the message is ultimately sent to is decided by the message service.
In order to avoid formatting messages which will not be sent because the verboseness level is too high, a MsgStream object first checks to see that a message will be printed before actually constructing it. However the threshold for a MsgStream object is not dynamic, i.e. it is set at creation time and remains the same. Thus in order to keep synchronized with the message service, which in principle could change its printout level at any time, MsgStream objects should be made locally on the stack when needed. For example, if you look at the listing of the HistoAlgorithm class (see also Listing 54 below) you will note that MsgStream objects are instantiated locally (i.e. not using new) in all three of the IAlgorithm methods and thus are destructed when the methods return. If this is not done messages may be lost, or too many messages may be printed.
The MsgStream class has been designed to resemble closely a normal stream class such as std::cout, and in fact internally uses an
ostrstream
object. All of the MsgStream member functions write unformatted data; formatted output is handled by the insertion operators.
An example use of the MsgStream class is shown below.
When using the MsgStream class just think of it as a configurable output stream whose activation is actually controlled by the first word (message level) and which actually prints only when "endreq" is supplied. For all other functionality simply refer to the C++
ostream
class.
The "activation level" of the MsgStream object is controlled by the first expression, e.g. MSG::ERROR or MSG::DEBUG in the example above. Possible values are given by the enumeration below:
enum MSG::Level { VERBOUS, DEBUG, INFO, WARNING, ERROR, FATAL }; |
Thus the code in Listing 54 will produce NO output if the print level of the message service is set higher than MSG::ERROR. In addition if the service's print level is lower than or equal to MSG::DEBUG the "Finalize completed successfully" message will be printed (assuming of course it was successful).
What follows is a technical description of the part of the MsgStream user interface most often seen by application developers. Please refer to the header file for the complete interface.
The MsgStream class overloads the '<<` operator as described below.
The MsgStream specific manipulators are presented below, e.g. endreq: MsgStream& endreq(MsgStream& stream). Besides these, the common
ostream
and ios manipulators such as std::ends, std::endl,... are also accepted.
The Particle Property service is a utility to find information about a named particle's Geant3 ID, Jetset/Pythia ID, Geant3 tracking type, charge, mass or lifetime. The database used by the service can be changed, but by default is the same as that used by SICb. Note that the units conform to the CLHEP convention, in particular MeV for masses and ns for lifetimes. Any comment to the contrary in the code is just a leftover which has been overlooked!
This service is created by default by the application manager, with the name "ParticlePropertySvc". Listing 50 on See Code to access the IParticlePropertySvc interface from an Algorithm shows how to access this service from within an algorithm.
The Particle Property Service currently only has one property:
ParticlePropertiesFile
. This string property is the name of the database file that should be used by the service to build up its list of particle properties. The default value of this property, on all platforms, is
$LHCBDBASE/cdf/particle.cdf
The service implements the
IParticlePropertySvc
interface which must be included when a client wishes to use the service - the file to include is
Gaudi/Interfaces/IParticlePropertySvc.h
The service itself consists of one STL vector to access all of the existing particle properties, and three STL maps, one to map particles by name, one to map particles by Geant3 ID and one to map particles by stdHep ID.
Although there are three maps, there is only one copy of each particle property and thus each property must have a unique particle name and a unique Geant3 ID. The third map does not contain all particles contained in the other two maps; this is because there are particles known to Geant but not to stdHep, such as Deuteron or Cerenkov. Although retrieving particles by name should be sufficient, the second and third maps are there because most of the data generated by SICb stores a particle's Geant3 ID or stdHep ID, and not the particle's name. These maps speed up searches using the IDs.
The IParticlePropertySvc interface provides the following functions:
The IParticlePropertySvc interface also provides some typedefs for easier coding:
Below are some extracts of code from the example in GaudiExamples/ParticleProperties, to show how one might use the service:
The Chrono & Stat service provides a facility to do time profiling of code ( Chrono part) and to do some statistical monitoring of simple quantities ( Stat part). The service is created by default by the Application Manager, with the name "ChronoStatSvc" and service ID extern const CLID& IID_IChronoStatSvc To access the service from inside an algorithm, the member function chronoSvc()is provided. The job Options to configure this service are described in Appendix B, Table B.19.
Profiling is performed by using the chronoStart() and chronoStop() methods inside the codes to be profiled, e.g:
/// ... IChronoStatSvc* svc = chronoSvc(); /// start svc->chronoStart( "Some Tag" ); /// here some user code are placed: ... /// stop svc->chronoStop( "SomeTag" ); |
The profiling information accumulates under the tag name given as argument to these methods. The service measures the time elapsed between subsequent calls of chronoStart() and chronoStop() with the same tag. The latter is important, since in the sequence of calls below, only the elapsed time between lines 3 and 5 lines and between lines 7 and 9 lines would be accumulated.:
The profiling information could be printed either directly using the chronoPrint() method of the service, or in the summary table of profiling information at the end of the job.
Note that this method of code profiling should be used only for fine grained monitoring inside algorithms. To profile a complete algorithm you should use the Auditor service, as described in section 11.7.
Statistical monitoring is performed by using the stat() method inside user code:
|
1:
/// ... Flag and Weight to be accumulated:
2:
svc->stat( " Number of Tracks " , Flag , Weight ); |
The statistical information contains the "accumulated" flag , which is the sum of all Flag s for the given tag, and the "accumulated" weight , which is the product of all Weight s for the given tag. The information is printed in the final table of statistics.
In some sense the profiling could be considered as statistical monitoring, where the variable Flag equals the elapsed time of the process.
To simplify the usage of the Chrono & Stat Service, two helper classes were developed: class Chrono and class Stat. Using these utilities, one hides the communications with Chrono & Stat Service and provides a more friendly environment.
Chrono is a small helper class which invokes the chronoStart() method in the constructor and the chronoStop() method in the destructor. It must be used as an automatic local object .
It performs the profiling of the code between its own creation and the end of the current scope, e.g:
|
1:
#include Gaudi/ChronoStatSvc/Chrono.h
2:
/// ...
3:
{ // begin of the scope
4:
Chrono chrono( chronoSvc() , "ChronoTag" ) ;
5:
/// some codes:
6:
...
7:
///
8:
} // end of the scope
9:
/// ... |
If the Chrono & Stat Service is not accessible, the Chrono object does nothing
The implementation of the Chrono & Stat Service uses two std::map containers and could generate a performance penalty for very frequent calls. Usually the penalty is small relative to the elapsed time of algorithms, but it is worth avoiding both the direct usage of the Chrono & Stat Service as well as the usage of it through the Chrono or Stat utilities inside internal loops:
The Auditor Service provides a set of auditors that can be used to provide monitoring of various characteristics of the execution of Algorithms. Each auditor is called immediately before and after each call to each Algorithm instance, and can track some resource usage of the Algorithm. Calls that are thus monitored are
initialize()
,
execute()
and
finalize()
, although monitoring can be disabled for any of these for particular Algorithm instances. Only the
execute()
function monitoring is enabled by default.
Several examples of auditors are provided. These are:
The Auditor Service is enabled by the following line in the Job Options file:
Specifying which auditors are enabled is illustrated by the following example:
By default, only monitoring of the Algorithm
execute()
function is enabled by default. This default can be overridden for individual Algorithms by use of the following Algorithm properties:
|
// Enable initialize and finalize auditing & disable execute auditing // for the myAlgorithm Algorithm myAlgorithm.AuditInitialize = true; |
The relevant portion of the
IAuditor
abstract interface is shown below:
A new Auditor should inherit from the Auditor base class and override the appropriate functions from the IAuditor abstract interface. The following code fragment is taken from the ChronoAuditor:
When generating random numbers two issues must be considered:
In order to ensure both, Gaudi implements a single service ensuring that these criteria are met. The encapsulation of the actual random generator into a service has several advantages:
The implementation of both generators and random number engines are taken from CLHEP. The default random number engine used by Gaudi is the RanLux engine of CLHEP with a luxury level of 3, which is also the default for Geant4, so as to use the same mechanism to generate random numbers as the detector simulation.
Figure 22 shows the general architecture of the Gaudi random number service. The client interacts with the service in the following way:
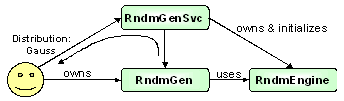
|
There are many different distributions available. The shape of the distribution must be supplied as a parameter when the generator is requested by the user.
Currently implemented distributions include the following:
(see also the header file
Gaudi/RndmGenSvc/RandomGenerators.h
for a description of the parameters to be supplied)
Rndm::Bit()
min, max
] with parameters:
Rndm::Flat(double min, double max)
Rndm::Gauss(double mean, double sigma)
Rndm::Poisson(double mean)
n
tests with a probability
p
with parameters:
Rndm::Binomial(long n, double p)
Rndm::Exponential(double mean)
n_dof
degrees of freedom with parameters:
Rndm::Chi2(long n_dof)
Rndm::BreitWigner(double mean, double gamma)
Rndm::BreitWignerCutOff (mean, gamma, cut-off)
Rndm::Landau(double mean, double sigma)
Rndm::DefinedPdf(const std::vector<double>& pdf, long intpol)
Clearly the supplied list of possible parameters is not exhaustive, but probably represents most needs. The list only represents the present content of generators available in CLHEP and can be updated in case other distributions will be implemented.
Since there is a danger that the interfaces are not released, a wrapper is provided that automatically releases all resources once the object goes out of scope. This wrapper allows the use of the random number service in a simple way. Typically there are two different usages of this wrapper:
|
1:
#include "Gaudi/RandmGenSvc/RndmGenerators.h"
2:
3:
// Constructor
4:
class myAlgorithm : public Algorithm {
5:
Rndm::Numbers m_gaussDist;
6:
...
7:
};
8:
9:
// Initialisation
10:
StatusCode myAlgorithm::initialize() {
11:
...
1:
StatusCode sc=m_gaussDist.initialize( randSvc(), Rndm::Gauss(0.5,0.2));
2:
if ( !status.isSuccess() ) {
3:
// put error handling code here...
4:
}
5:
...
6:
} |
There are a few points to be mentioned in order to ensure the reproducibility:
The Incident service provides synchronization facilities to components in a Gaudi application. Incidents are named software events that are generated by software components and that are delivered to other components that have requested to be informed when that incident happens. The Gaudi components that want to use this service need to implement the
IIncidentListener
interface, which has only one method:
handle(Incident&),
and they need to add themselves as Listeners to the IncidentSvc. The following code fragment works inside Algorithms.
The third argument in method
addListener()
is for specifying the priority by which the component will be informed of the incident in case several components are listeners of the same named incident. This parameter is used by the
IncidentSvc
to sort the listeners in order of priority.
Within Gaudi we use the term "Service" to refer to a class whose job is to provide a set of facilities or utilities to be used by other components. In fact we mean more than this because a concrete service must derive from the Service base class and thus has a certain amount of predefined behaviour; for example it has initialize() and finalize() methods which are invoked by the application manager at well defined times.
Figure 23 shows the inheritance structure for an example service called SpecificService (!). The key idea is that a service should derive from the Service base class and additionally implement one or more pure abstract classes (interfaces) such as IConcreteSvcType1 and IConcreteSvcType2 in the figure.
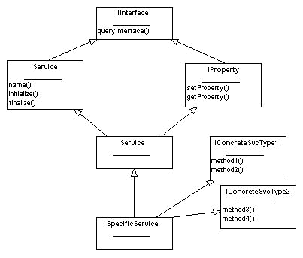
|
As discussed above, it is necessary to derive from the Service base class so that the concrete service may be made accessible to other Gaudi components. The actual facilities provided by the service are available via the interfaces that it provides. For example the ParticleProperties service implements an interface which provides methods for retrieving, for example, the mass of a given particle. In figure 23 the service implements two interfaces each of two methods.
A component which wishes to make use of a service makes a request to the application manager. Services are requested by a combination of name, and interface type, i.e. an algorithm would request specifically either IConcreteSvcType1 or IConcreteSvcType2.
The identification of what interface types are implemented by a particular class is done via the queryInterface method of the IInterface interface. This method must be implemented in the concrete service class. In addition the initialize() and finalize() methods should be implemented. After initialization the service should be in a state where it may be used by other components.
The service base class offers a number of facilities itself which may be used by derived concrete service classes:
The following is essentially a checklist of the minimal code required for a service.