| | |
GAUDI User Guide
| | |
GAUDI User Guide

The data stores are a key component in the application framework. All data which comes from persistent storage, or which is transferred between algorithms, or which is to be made persistent must reside within a data store. In this chapter we look at how to access data within the stores, and also at the DataObject base class and some classes related to it.
We also cover how to define your own data types and the steps necessary to save newly created objects to disk files. The writing of the converters necessary for the latter is covered in chapter 13.
There are four data stores currently implemented within the Gaudi framework: the event data store, the detector data store, the histogram store and the n-tuple store. They are described in chapters 7, 8, 9 and 10 respectively. The stores themselves are no more than logical constructs with the actual access to the data being via the corresponding services. Both the event data service and the detector data service implement the same IDataProviderSvc interface, which can be used by algorithms to retrieve and store data. The histogram and n-tuple services implement extended versions of this interface (IHistogramSvc, INTupleSvc) which offer methods for creating and manipulating histograms and n-tuples, in addition to the data access methods provided by the other two stores.
Only objects of a type derived from the DataObject base class may be placed directly within a data store. Within the store the objects are arranged in a tree structure, just like a Unix file system. As an example consider Figure 7 which shows a part of the LHCb transient data model. An object is identified by its position in the tree expressed as a string such as: "/Event", or "/Event/MC/MCParticles". In principle the structure of the tree, i.e. the set of all valid paths, may be deduced at run time by making repeated queries to the event data service, but this is unlikely to be useful in general since the structure will be largely fixed.
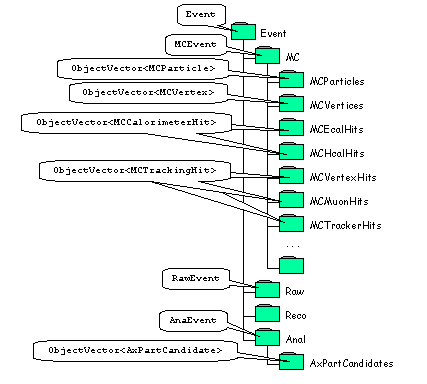
|
As stated above all interactions between the data stores and algorithms should be via the IDataProviderSvc interface. The key methods for this interface are shown in Listing 12.
The first four methods are for retrieving a pointer to an object that is already in the store. How the object got into the store, whether it has been read in from a persistent store or added to the store by an algorithm, is irrelevant.
The find and retrieve methods come in two versions: One version uses a full path name as an object identifier, the other takes a pointer to a previously retrieved object and the name of the object to look for below that node in the tree.
Additionally the "find" and "retrieve" methods differ in one important respect: the "find" method will look in the store to see if the object is present (i.e. in memory) and if it is not will return a null pointer. The "retrieve" method, however, will attempt to load the object from a persistent store (database or file) if it is not found in memory. Only if it is not found in the persistent data store will the method return a null pointer (and a bad status code of course).
Whatever the concrete type of the object you have retrieved from the store the pointer which you have is a pointer to a DataObject, so before you can do anything useful with that object you must cast it to the correct type, for example:
The
typedef
on line 1 is just to save typing;
typedef
s of this kind are defined for all
ObjectVector
s in the LHCb data model, in what follows we will use the two syntaxes interchangeably. After the
dynamic_cast
on line 10 all of the methods of the MCParticleVector class become available. In the event that the object which is returned from the store does not match the type to which you try to cast it, an exception will be thrown. If you do not catch this exception it will be caught by the algorithm base class, and the program will stop, probably with an obscure message. A more elegant way to retrieve the data involves the use os Smart Pointers - this is discussed in section 6.8
As mentioned earlier a certain amount of run-time investigation may be done into what data is available in the store. For example, suppose that we have various sets of testbeam data and each data set was taken with a different number of detectors. If the raw data is saved on a per-detector basis the number of sets will vary. The code fragment in Listing 13 illustrates how an algorithm may loop over the data sets without knowing a priori how many there are.
The last two methods shown in Listing 12 are for registering objects into the store. Suppose that an algorithm creates objects of type UDO from, say, objects of type MCParticle and wishes to place these into the store for use by other algorithms. Code to do this might look something like:
Once an object is registered into the store, the algorithm which created it relinquishes ownership. In other words the object should not be deleted. This is also true for objects which are contained within other objects, such as those derived from or instantiated from the ObjectVector class (see the following section). Furthermore objects which are to be registered into the store must be created on the heap, i.e. they must be created with the new operator.
As mentioned before, all objects which can be placed directly within one of the stores must be derived from the DataObject class. There is, however, another (indirect) way to store objects within a store. This is by putting a set of objects (themselves not derived from
DataObject
and thus not directly storable) into an object which is derived from DataObject and which may thus be registered into a store.
An object container base class is implemented within the framework and a number of templated object container classes may be implemented in the future. For the moment, two "concrete" container classes are implemented: ObjectVector<T> and
ObjectList<T>
. These classes are based upon the STL classes and provide mostly the same interface. Unlike the STL containers which are essentially designed to hold objects, the container classes within the framework contain only pointers to objects, thus avoiding a lot of memory to memory copying.
A further difference with the STL containers is that the type T cannot be anything you like. It must be a type derived from the ContainedObject base class, see Figure 8. In this way all "contained" objects have a pointer back to their containing object. This is required, in particular, by the converters for dealing with links between objects. A ramification of this is that container objects may not contain other container objects (without the use of multiple inheritance).
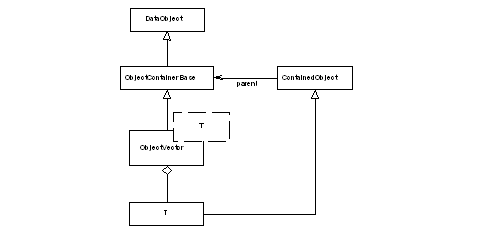
|
As mentioned above, objects which are contained within one of these container objects may not be located, or registered, individually within the store. Only the container object may be located via a call to findObject() or retrieveObject(). Thus with regard to interaction with the data stores a container object and the objects that it contains behave as a single object.
The intention is that "small" objects such as clusters, hits, tracks, etc. are derived from the ContainedObject base class and that in general algorithms will take object containers as their input data and produce new object containers of a different type as their output.
The reason behind this is essentially one of optimization. If all objects were treated on an equal footing, then there would be many more accesses to the persistent store to retrieve very small objects. By grouping objects together like this we are able to have fewer accesses, with each access retrieving bigger objects.
The code fragment below shows the creation of an object container. This container can contain pointers to objects of type MCTrackingHit and only to objects of this type (including derived types). An object of the required type is created on the heap (i.e. via a call to new) and is added to the container with the standard STL call.
ObjectVector <MCTrackingHit> hitContainer;MCTrackingHit* h1 = new MCTrackingHit;hitContainer.push_back(h1); |
After the call to push_back() the hit object "belongs" to the container. If the container is registered into the store, the hits that it contains will go with it. Note in particular that if you delete the container you will also delete its contents, i.e. all of the objects pointed to by the pointers in the container.
Removing an object from a container may be done in two semantically different ways. The difference being whether on removal from a container the object is also deleted or not. Removal with deletion may be achieved in several ways (following previous code fragment):
hitContainer.pop_back();hitContainer.erase( end() );delete h1; |
The method pop_back() removes the last element in the container, whereas erase() maybe used to remove any other element via an iterator. In the code fragment above it is used to remove the last element also.
Deleting a contained object, the third option above, will automatically trigger its removal from the container. This is done by the destructor of the ContainedObject base class.
If you wish to remove an object from the container without destroying it (the second possible semantic) use the release() method:
hitContainer.release(h1); |
Since the fate of a contained object is so closely tied to that of its container life would become more complex if objects could belong to more than one container. Suppose that an object belonged to two containers, one of which was deleted. Should the object be deleted and removed from the second container, or not deleted? To avoid such issues an object is allowed to belong to a single container only.
If you wish to move an object from one container to another, you must first remove it from one and then add to the other. However, the first operation is done implicitly for you when you try to add an object to a second container:
container1.push_back(h1); // Add to fist containercontainer2.push_back(h1); // Move to second container // Internally invokes release(). |
Since the object h1 has a link back to its container, the push_back() method is able to first follow this link and invoke the release() method to remove the object from the first container, before adding it into the second.
In general your first exposure to object containers is likely to be when retrieving data from the event data store. The sample code in Listing 15 shows how, once you have retrieved an object container from the store you may iterate over its contents, just as with an STL vector.
The variable tracks is set to point to an object in the event data store of type: ObjectVector<MCParticle> with a dynamic cast (not shown above). An iterator (i.e. a pointer like object for looping over the contents of the container) is defined on line 3 and this is used within the loop to point consecutively to each of the contained objects. In this case the objects contained within the ObjectVector are of type "pointer to
MCParticle
". The iterator returns each object in turn and in the example, the energy of the object is used to fill a histogram.
Most of the data types which will be used within Gaudi will be used by everybody and thus packaged and documented centrally. However, for your own private development work you may wish to create objects of your own types which of course you can always do with C++ (or Java) . However, if you wish to place these objects within a store, either so as to pass them between algorithms or to have them later saved into a database or file, then you must derive your type from either the DataObject or ContainedObject base class.
This defines a class UDO which since it derives from DataObject may be registered into, say, the event data store. (The class itself is not very useful as its sole attribute is a single integer and it has no behaviour).
The thing to note here is that if the appropriate converter is supplied, as discussed in Chapter 13, then this class may also be saved into a persistent store (e.g. a ROOT file or an Objectivity database) and read back at a later date. In order for the persistency to work the following are required: the unique class identifier number (
CLID_UDO
in the example), and the clID() and classID() methods which return this identifier.
The procedure for allocating unique class identifiers in LHCb, and the list of already allocated identifiers, are available at http://cern.ch/lhcb-comp/Support/html/CLID.htm
Types which are derived from ContainedObject are implemented in the same way, and must have a
CLID
in the range of an
unsigned short
. Contained objects may only reside in the store when they belong to a container, e.g. an ObjectVector<T> which is registered into the store. The class identifier of a concrete object container class is calculated (at run time) from the type of the objects which it contains, by setting bit 16. The static classID() method is required because the container may be empty.
The usage of the data services is simple, but extensive status checking and other things tend to make the code difficult to read. It would be more convenient to access data items in the store in a similar way to accessing objects with a C++ pointer. This is achieved with smart pointers, which hide the internals of the data services.
The
SmartDataPtr
and a
SmartDataLocator
are smart pointers that differ by the access to the data store.
SmartDataPtr
first checks whether the requested object is present in the transient store and loads it if necessary (similar to the
retrieveObject
method of
IDataProviderSvc
).
SmartDataLocator
only checks for the presence of the object but does not attempt to load it (similar to
findObject
).
Both
SmartDataPtr
and
SmartDataLocator
objects use the data service to get hold of the requested object and deliver it to the user. Since both objects have similar behaviour and the same user interface, in the following only the
SmartDataPtr
is discussed.
An example use of the SmartDataPtr class is shown below.
The SmartDataPtr class can be thought of as a normal C++ pointer having a constructor. It is used in the same way as a normal C++ pointer.
The
SmartDataPtr
and
SmartDataLocator
offer a number of possible constructors and operators to cover a wide range of needs when accessing data stores. Check the online reference documentation [2] for up-to date information concerning the interface of these utilities.
Smart references and Smart reference vectors are similar to smart pointers, they are used within data objects to reference other objects in the transient data store. They provide safe data access and automate the loading on demand of referenced data, and should be used instead of C++ pointers. For example, suppose that
MCParticles
are already loaded but
MCVertices
are not, and that an algorithm dereferences a variable pointing to the origin vertex: if a smart reference is used, the
MCVertices
would be loaded automatically and only after that would the variable be dereferenced. If a C++ plain pointer were used instead, the program would crash. Smart references provide an automatic conversion to a pointer to the object and load the object from the persistent medium during the conversion process.
Smart references and Smart reference vectors are declared inside a class as:
The syntax of usage of smart references is identical to plain C++ pointers. The Algorithm only sees a pointer to the
MCVertex
object:
All LHCbEvent data types use the Smart references and Smart reference vectors to reference themselves.
Suppose that you have defined your own data type as discussed in section 6.7. Suppose futhermore that you have an algorithm which uses, say, SicB data to create instances of your object type which you then register into the transient event store. How can you save these objects for use at a later date?
execute()
method of your algorithm.
// myAlg implementation file StatusCode myAlg::execute() { // Create a UDO object and register it into the event data store UDO* p = new UDO(); eventSvc->registerObject("/Event/myStuff/myUDO", p);} |
In order to actually trigger the conversion and saving of the objects at the end of the current event processing it is necessary to inform the application manager. This requires some options to be specified in the job options file:
The first option tells the application manager that you wish to create an output stream called "
DstWriter
". You may create as many output streams as you like and give them whatever name you prefer.
For each output stream object which you create you must set several properties. The ItemList option specifies the list of paths to the objects which you wish to write to this output stream. The number after the "#" symbol denotes the number of directory levels below the specified path which should be traversed. The (optional) EvtDataSvc option specifies in which transient data service the output stream should search for the objects in the ItemList, the default is the standard transient event data service
EventDataSvc
. The
Output
option specifies the name of the output data file and the type of persistency technology,
ROOT
in this example. The last three options are needed to tell the Application manager to instantiate the
RootEvtCnvSvc
and to associate the
ROOT
persistency type to this service.
An example of saving data to a ROOT persistent data store is available in the
Rio.Example1
distributed with the framework.